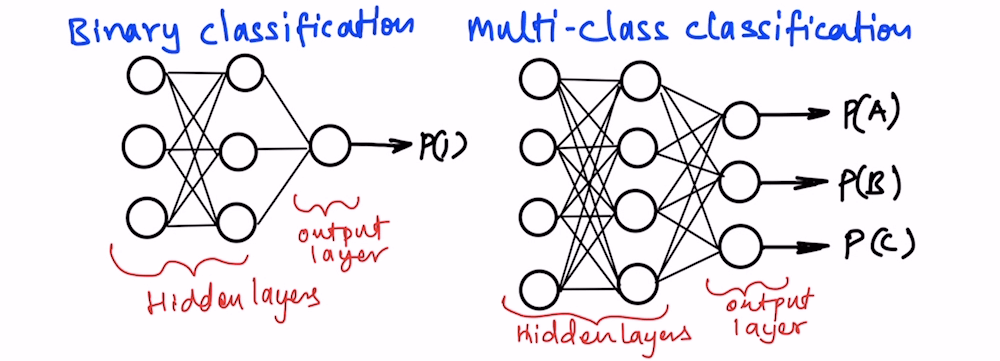
In the previous post, I talked about how to use Artificial Neural Networks(ANNs) for regression use cases. In this post, I will show you how to use ANN for classification.
There is a slight difference in the configuration of the output layer as listed below.
- Regression: One neuron in the output layer
- Classification(Binary): Two neurons in the output layer
- Classification(Multi-class): The number of neurons in the output layer is equal to the unique classes, each representing 0/1 output for one class
You can watch the below video to get an understanding of how ANNs work.
I am using the famous Titanic survival data set to illustrate the use of ANN for classification.
The pre-processing and feature selection has been done in this previous case study.
Data description
The business meaning of each column in the data is as below
You can download the data required for this case study here.
- Survived: Whether the passenger survived or not? 1=Survived, 0=Died
- Pclass: The travel class of the passenger
- Sex: The gender of the passenger
- Age: The Age of the passenger
- SibSp: Number of Siblings/Spouses Aboard
- Parch: Number of Parents/Children Aboard
- Fare: The amount of fare paid by the passenger
- Embarked: Port of Embarkation (C = Cherbourg; Q = Queenstown; S = Southampton)
Loading the data
|
1 2 3 4 5 6 7 8 9 |
# Reading the cleaned numeric titanic survival data import pandas as pd import numpy as np # To remove the scientific notation from numpy arrays np.set_printoptions(suppress=True) TitanicSurvivalDataNumeric=pd.read_pickle('TitanicSurvivalDataNumeric.pkl') TitanicSurvivalDataNumeric.head() |

Defining the problem statement:
Create a Predictive model that can tell if a person will survive the titanic crash or not?
- Target Variable: Survived
- Predictors: age, sex, passenger class, etc.
- Survived=0 The passenger died
- Survived=1 The passenger survived
Splitting the Data into Training and Testing
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# Separate Target Variable and Predictor Variables TargetVariable=['Survived'] Predictors=['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked_C', 'Embarked_Q', 'Embarked_S'] X=TitanicSurvivalDataNumeric[Predictors].values y=TitanicSurvivalDataNumeric[TargetVariable].values ### Sandardization of data ### ### We does not standardize the Target variable for classification from sklearn.preprocessing import StandardScaler PredictorScaler=StandardScaler() # Storing the fit object for later reference PredictorScalerFit=PredictorScaler.fit(X) # Generating the standardized values of X and y X=PredictorScalerFit.transform(X) # Split the data into training and testing set from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # Quick sanity check with the shapes of Training and Testing datasets print(X_train.shape) print(y_train.shape) print(X_test.shape) print(y_test.shape) |

Creating Deep Learning ANN model
Using the sampled data, creating the ANN classification model. Please note that the output layer has one neuron here because this is a binary classification problem. If there were multiple classes then we will have to choose those many neurons, like for 5 classes, the output layer will have 5 neurons, each giving the probability of that class, whichever class has the highest probability, becomes the final answer.
Here I have used two hidden layers, First has 10 neurons, and the second has 6 neurons. The output layer has one neuron. Which give the probability of class “1”.
How many neurons should you choose? How many hidden layers should you choose? This is something which varies from data to data, you need to check the testing accuracy and decide which combination is working best. This is why tuning ANN is a difficult task, because there are so many parameters and configurations which can be changed.
Take a look at some of the important hyper parameters of ANN below
- units=10: This means we are creating a layer with ten neurons in it. Each of these five neurons will be receiving the values of inputs, for example, the values of ‘Age’ will be passed to all five neurons, similarly all other columns.
- input_dim=9: This means there are nine predictors in the input data which is expected by the first layer. If you see the second dense layer, we don’t specify this value, because the Sequential model passes this information further to the next layers.
- kernel_initializer=’uniform’: When the Neurons start their computation, some algorithm has to decide the value for each weight. This parameter specifies that. You can choose different values for it like ‘normal’ or ‘glorot_uniform’.
- activation=’relu’: This specifies the activation function for the calculations inside each neuron. You can choose values like ‘relu’, ‘tanh’, ‘sigmoid’, etc.
- optimizer=’adam’: This parameter helps to find the optimum values of each weight in the neural network. ‘adam’ is one of the most useful optimizers, another one is ‘rmsprop’
- batch_size=10: This specifies how many rows will be passed to the Network in one go after which the SSE calculation will begin and the neural network will start adjusting its weights based on the errors.
When all the rows are passed in the batches of 10 rows each as specified in this parameter, then we call that 1-epoch. Or one full data cycle. This is also known as mini-batch gradient descent. A small value of batch_size will make the ANN look at the data slowly, like 2 rows at a time or 4 rows at a time which could lead to overfitting, as compared to a large value like 20 or 50 rows at a time, which will make the ANN look at the data fast which could lead to underfitting. Hence a proper value must be chosen using hyperparameter tuning. - Epochs=10: The same activity of adjusting weights continues for 10 times, as specified by this parameter. In simple terms, the ANN looks at the full training data 10 times and adjusts its weights.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
classifier = Sequential() # Defining the Input layer and FIRST hidden layer,both are same! # relu means Rectifier linear unit function classifier.add(Dense(units=10, input_dim=9, kernel_initializer='uniform', activation='relu')) #Defining the SECOND hidden layer, here we have not defined input because it is # second layer and it will get input as the output of first hidden layer classifier.add(Dense(units=6, kernel_initializer='uniform', activation='relu')) # Defining the Output layer # sigmoid means sigmoid activation function # for Multiclass classification the activation ='softmax' # And output_dim will be equal to the number of factor levels classifier.add(Dense(units=1, kernel_initializer='uniform', activation='sigmoid')) # Optimizer== the algorithm of SGG to keep updating weights # loss== the loss function to measure the accuracy # metrics== the way we will compare the accuracy after each step of SGD classifier.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) # fitting the Neural Network on the training data survivalANN_Model=classifier.fit(X_train,y_train, batch_size=10 , epochs=10, verbose=1) # fitting the Neural Network on the training data survivalANN_Model=classifier.fit(X_train,y_train, batch_size=10 , epochs=10, verbose=1) |

Hyperparameter tuning of ANN
As mentioned above, the hyperparameter tuning for ANN is a big task! You can make your own function and iterate thru the values to try or use the GridSearchCV module from sklearn library.
There is no thumb rule which can help you to decide the number of layers/number of neurons etc. in the first look at data. You need to try different parameters and choose the combination which produces the highest accuracy.
Just keep in mind, that, the bigger the network, the more computationally intensive it is, hence it will take more time to run. So always to find the best accuracy with the minimum number of layers/neurons.
Hyperparameter tuning using Manual Grid Search
This method can be changed easily to suit your requirements. You can decide what you need to iterate and add another nested for-loop.
In the below snippet, I have searched for best batch_size and epochs.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
# Defining a function for finding best hyperparameters def FunctionFindBestParams(X_train, y_train): # Defining the list of hyper parameters to try TrialNumber=0 batch_size_list=[5, 10, 15, 20] epoch_list=[5, 10, 50 ,100] import pandas as pd SearchResultsData=pd.DataFrame(columns=['TrialNumber', 'Parameters', 'Accuracy']) for batch_size_trial in batch_size_list: for epochs_trial in epoch_list: TrialNumber+=1 # Creating the classifier ANN model classifier = Sequential() classifier.add(Dense(units=10, input_dim=9, kernel_initializer='uniform', activation='relu')) classifier.add(Dense(units=6, kernel_initializer='uniform', activation='relu')) classifier.add(Dense(units=1, kernel_initializer='uniform', activation='sigmoid')) classifier.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) survivalANN_Model=classifier.fit(X_train,y_train, batch_size=batch_size_trial , epochs=epochs_trial, verbose=0) # Fetching the accuracy of the training Accuracy = survivalANN_Model.history['accuracy'][-1] # printing the results of the current iteration print(TrialNumber, 'Parameters:','batch_size:', batch_size_trial,'-', 'epochs:',epochs_trial, 'Accuracy:', Accuracy) SearchResultsData=SearchResultsData.append(pd.DataFrame(data=[[TrialNumber, 'batch_size'+str(batch_size_trial)+'-'+'epoch'+str(epochs_trial), Accuracy]], columns=['TrialNumber', 'Parameters', 'Accuracy'] )) return(SearchResultsData) ############################################### # Calling the function ResultsData=FunctionFindBestParams(X_train, y_train) |

Looking at the best hyperparameter
From the results data above, simply sorting the data on accuracy and getting that combination which has the highest accuracy.
Based on the below output, you can notice that the best parameters are batch_size=5 and epoch=100.
|
1 2 3 4 5 6 |
# Printing the best parameter print(ResultsData.sort_values(by='Accuracy', ascending=False).head(1)) # Visualizing the results %matplotlib inline ResultsData.plot(x='Parameters', y='Accuracy', figsize=(15,4), kind='line', rot=20) |

Training the model using best hyperparameters
|
1 2 |
# Training the model with best hyperparamters classifier.fit(X_train,y_train, batch_size=5 , epochs=100, verbose=1) |

Why the accuracy comes different every time I train ANN?
Even when you use the same hyperparameters, the result will be slightly different for each run of ANN. This happens because the initial step for ANN is the random initialization of weights. So every time you run the code, there are different values that get assigned to each neuron as weights and bias, hence the final outcome also differs slightly.
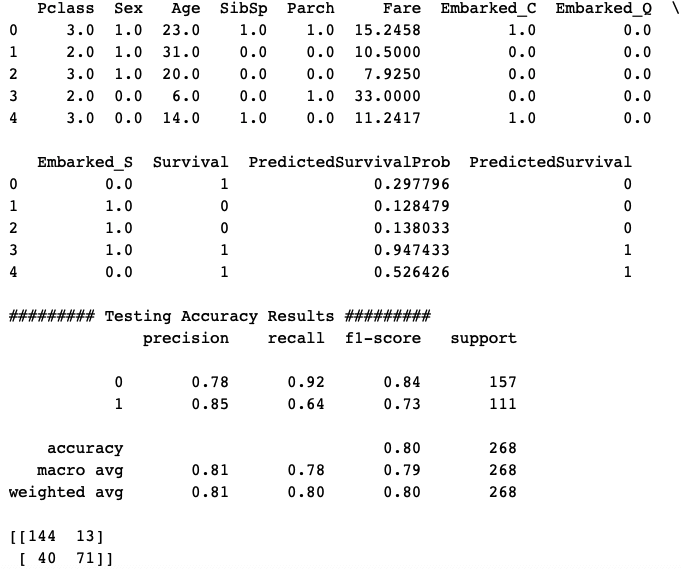
Checking model accuracy on Testing Data
Calculating the accuracy of the final trained model above on the testing data.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# Predictions on testing data Predictions=classifier.predict(X_test) # Scaling the test data back to original scale Test_Data=PredictorScalerFit.inverse_transform(X_test) # Generating a data frame for analyzing the test data TestingData=pd.DataFrame(data=Test_Data, columns=Predictors) TestingData['Survival']=y_test TestingData['PredictedSurvivalProb']=Predictions # Defining the probability threshold def probThreshold(inpProb): if inpProb > 0.5: return(1) else: return(0) # Generating predictions on the testing data by applying probability threshold TestingData['PredictedSurvival']=TestingData['PredictedSurvivalProb'].apply(probThreshold) print(TestingData.head()) ############################################### from sklearn import metrics print('\n######### Testing Accuracy Results #########') print(metrics.classification_report(TestingData['Survival'], TestingData['PredictedSurvival'])) print(metrics.confusion_matrix(TestingData['Survival'], TestingData['PredictedSurvival'])) |
Finding the best ANN hyperparameters using GridSearchCV.
Apart from the manual search method shown above, you can also use the Grid Search Cross-validation method present in the sklearn library to find the best parameters of ANN.
The below snippet defines some parameter values to try and finds the best combination out of it.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
# Function to generate Deep ANN model def make_classification_ann(Optimizer_Trial, Neurons_Trial): from keras.models import Sequential from keras.layers import Dense # Creating the classifier ANN model classifier = Sequential() classifier.add(Dense(units=Neurons_Trial, input_dim=9, kernel_initializer='uniform', activation='relu')) classifier.add(Dense(units=Neurons_Trial, kernel_initializer='uniform', activation='relu')) classifier.add(Dense(units=1, kernel_initializer='uniform', activation='sigmoid')) classifier.compile(optimizer=Optimizer_Trial, loss='binary_crossentropy', metrics=['accuracy']) return classifier ######################################## from sklearn.model_selection import GridSearchCV from keras.wrappers.scikit_learn import KerasClassifier Parameter_Trials={'batch_size':[10,20,30], 'epochs':[10,20], 'Optimizer_Trial':['adam', 'rmsprop'], 'Neurons_Trial': [5,10] } # Creating the classifier ANN classifierModel=KerasClassifier(make_classification_ann, verbose=0) ######################################## # Creating the Grid search space # See different scoring methods by using sklearn.metrics.SCORERS.keys() grid_search=GridSearchCV(estimator=classifierModel, param_grid=Parameter_Trials, scoring='f1', cv=5) ######################################## # Measuring how much time it took to find the best params import time StartTime=time.time() # Running Grid Search for different paramenters grid_search.fit(X_train,y_train, verbose=1) EndTime=time.time() print("############### Total Time Taken: ", round((EndTime-StartTime)/60), 'Minutes #############') ######################################## # printing the best parameters print('\n#### Best hyperparamters ####') grid_search.best_params_ |

Conclusion
This template can be used to fit the Deep Learning ANN classification model on any given dataset.
You can take the pre-processing steps of raw data from any of the case studies here.
Deep ANNs work great when you have a good amount of data available for learning. For small datasets with less than 50K records, I will recommend using the supervised ML models like Random Forests, Adaboosts, XGBoosts, etc.
The simple reason behind this is the high complexity and large computations of ANN. It is not worth it, if you can achieve the same accuracy with a faster and simpler model.
You look at deep learning ANNs only when you have a large amount of data available and the other algorithms are failing or do not fit for the task.

Not only coding required but also “GUESSING” hyperparameters ! Who can guess proper hyperparameters to fit NN’s to datasets ? And that is the main HUGE drawback on using NN software. Are u aware how many possibilities there exists, and who can test all those possibilities manually ??? The god damn whole NN structure is one big guess. There are even more possibilities as playing and winning a Lotto ! Until those software doesn’t have better auto learners integrated is completely useless. Guessing in science is not an really usable option.