Artificial Neural Networks(ANN) can be used for a wide variety of tasks, from face recognition to self-driving cars to chatbots! To understand more about ANN in-depth please read this post and watch the below video!
ANN can be used for supervised ML regression problems as well.
In this post, I am going to show you how to implement a Deep Learning ANN for a Regression use case.
I am using the pre-processed data from a previous case study on predicting old car prices. You can check the data cleansing and feature selection steps there.
Data description
You can download the data pickle file required for this case study here.
The business meaning of each column in the data is as below
- Price: The Price of the car in dollars
- Age: The age of the car in months
- KM: How many KMS did the car was used
- HP: Horsepower of the car
- MetColor: Whether the car has a metallic color or not
- CC: The engine size of the car
- Doors: The number of doors in the car
- Weight: The weight of the car
Create an ML model which can predict the apt price of a second-hand car.
Defining the problem statement:
- Target Variable: Price
- Predictors: Age, KM, CC, etc.
Loading the data for regression
I am loading the preprocessed data ‘CarPricesData.pkl’. This data is the final list of features selected for ML.
|
1 2 3 4 5 6 7 8 9 |
# Reading the cleaned numeric car prices data import pandas as pd import numpy as np # To remove the scientific notation from numpy arrays np.set_printoptions(suppress=True) CarPricesDataNumeric=pd.read_pickle('CarPricesData.pkl') CarPricesDataNumeric.head() |

Splitting the Data into Training and Testing
We don’t use the full data for creating the model. Some data is randomly selected and kept aside for checking how good the model is. This is known as Testing Data and the remaining data is called Training data on which the model is built. Typically 70% of data is used as Training data and the rest 30% is used as Testing data.
In this same step, we are standardizing the data as well. This is important for Neural Networks because it improves the model training speed and helps to find global minima.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# Separate Target Variable and Predictor Variables TargetVariable=['Price'] Predictors=['Age', 'KM', 'Weight', 'HP', 'MetColor', 'CC', 'Doors'] X=CarPricesDataNumeric[Predictors].values y=CarPricesDataNumeric[TargetVariable].values ### Sandardization of data ### from sklearn.preprocessing import StandardScaler PredictorScaler=StandardScaler() TargetVarScaler=StandardScaler() # Storing the fit object for later reference PredictorScalerFit=PredictorScaler.fit(X) TargetVarScalerFit=TargetVarScaler.fit(y) # Generating the standardized values of X and y X=PredictorScalerFit.transform(X) y=TargetVarScalerFit.transform(y) # Split the data into training and testing set from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # Quick sanity check with the shapes of Training and testing datasets print(X_train.shape) print(y_train.shape) print(X_test.shape) print(y_test.shape) |

Installing the required libraries
To implement deep learning ANNs, two libraries are required, ‘tensorflow‘ and ‘keras‘.
|
1 2 3 |
# Installing required libraries !pip install tensorflow !pip install keras |
Creating Deep Learning- Artificial Neural Networks(ANN) model
The architecture of a Deep Learning ANN used in this case study is shown below
I am using two hidden layers with five neurons each and one output layer with one neuron. Can you change these numbers? Yes, you can change the number of hidden layers and the number of neurons in each layer.
Finally, choose the combination that produces the best possible accuracy. This is the process of tuning the ANN model.
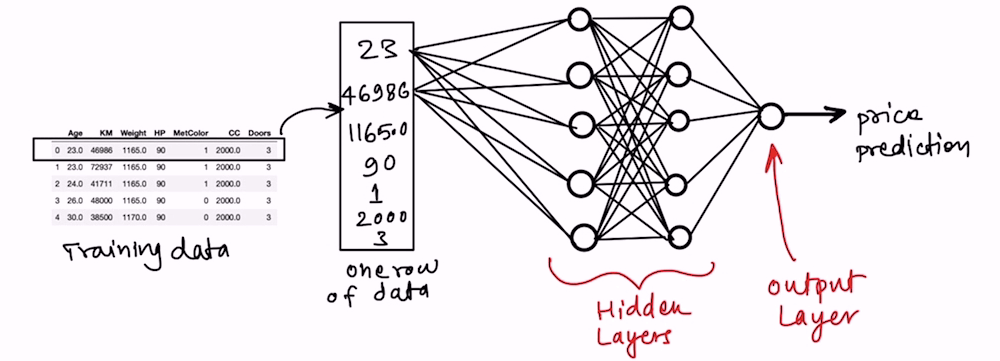
In the below code snippet, the “Sequential” module from the Keras library is used to create a sequence of ANN layers stacked one after the other. Each layer is defined using the “Dense” module of Keras where we specify how many neurons would be there, which technique would be used to initialize the weights in the network. what will be the activation function for each neuron in that layer etc
Lets quickly understand the hyperparameters in below code snippets
- units=5: This means we are creating a layer with five neurons in it. Each of these five neurons will be receiving the values of inputs, for example, the values of ‘Age’ will be passed to all five neurons, similarly all other columns.
- input_dim=7: This means there are seven predictors in the input data which is expected by the first layer. If you see the second dense layer, we don’t specify this value, because the Sequential model passes this information further to the next layers.
- kernel_initializer=’normal’: When the Neurons start their computation, some algorithm has to decide the value for each weight. This parameter specifies that. You can choose different values for it like ‘normal’ or ‘glorot_uniform’.
- activation=’relu’: This specifies the activation function for the calculations inside each neuron. You can choose values like ‘relu’, ‘tanh’, ‘sigmoid’, etc.
- batch_size=20: This specifies how many rows will be passed to the Network in one go after which the SSE calculation will begin and the neural network will start adjusting its weights based on the errors.
When all the rows are passed in the batches of 20 rows each as specified in this parameter, then we call that 1-epoch. Or one full data cycle. This is also known as mini-batch gradient descent. A small value of batch_size will make the ANN look at the data slowly, like 2 rows at a time or 4 rows at a time which could lead to overfitting, as compared to a large value like 20 or 50 rows at a time, which will make the ANN look at the data fast which could lead to underfitting. Hence a proper value must be chosen using hyperparameter tuning. - Epochs=50: The same activity of adjusting weights continues for 50 times, as specified by this parameter. In simple terms, the ANN looks at the full training data 50 times and adjusts its weights.
To understand more about these calculations which happen inside a neuron, refer to this post.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# importing the libraries from keras.models import Sequential from keras.layers import Dense # create ANN model model = Sequential() # Defining the Input layer and FIRST hidden layer, both are same! model.add(Dense(units=5, input_dim=7, kernel_initializer='normal', activation='relu')) # Defining the Second layer of the model # after the first layer we don't have to specify input_dim as keras configure it automatically model.add(Dense(units=5, kernel_initializer='normal', activation='tanh')) # The output neuron is a single fully connected node # Since we will be predicting a single number model.add(Dense(1, kernel_initializer='normal')) # Compiling the model model.compile(loss='mean_squared_error', optimizer='adam') # Fitting the ANN to the Training set model.fit(X_train, y_train ,batch_size = 20, epochs = 50, verbose=1) |

Hyperparameter tuning of ANN
Finding the best values for batch_size and epoch is very important as it directly affects the model performance. Bad values can lead to overfitting or underfitting. I am showing two approaches for tuning the parameters of the ANN. Apart from epoch and batch_size, you can also choose to tune the optimal number of neurons, the optimal number of layers, etc.
There is no thumb rule which can help you to decide the number of layers/number of neurons etc. in the first look at data. You need to try different parameters and choose the combination which produces the highest accuracy.
Just keep in mind, that, the bigger the network, the more computationally intensive it is, hence it will take more time to run. So always to find the best accuracy with the minimum number of layers/neurons.
Finding best set of parameters using manual grid search
This is a simple for loop based approach. You can easily edit this and adapt it for more hyperparameters by simply adding another nested for-loop.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
# Defining a function to find the best parameters for ANN def FunctionFindBestParams(X_train, y_train, X_test, y_test): # Defining the list of hyper parameters to try batch_size_list=[5, 10, 15, 20] epoch_list = [5, 10, 50, 100] import pandas as pd SearchResultsData=pd.DataFrame(columns=['TrialNumber', 'Parameters', 'Accuracy']) # initializing the trials TrialNumber=0 for batch_size_trial in batch_size_list: for epochs_trial in epoch_list: TrialNumber+=1 # create ANN model model = Sequential() # Defining the first layer of the model model.add(Dense(units=5, input_dim=X_train.shape[1], kernel_initializer='normal', activation='relu')) # Defining the Second layer of the model model.add(Dense(units=5, kernel_initializer='normal', activation='relu')) # The output neuron is a single fully connected node # Since we will be predicting a single number model.add(Dense(1, kernel_initializer='normal')) # Compiling the model model.compile(loss='mean_squared_error', optimizer='adam') # Fitting the ANN to the Training set model.fit(X_train, y_train ,batch_size = batch_size_trial, epochs = epochs_trial, verbose=0) MAPE = np.mean(100 * (np.abs(y_test-model.predict(X_test))/y_test)) # printing the results of the current iteration print(TrialNumber, 'Parameters:','batch_size:', batch_size_trial,'-', 'epochs:',epochs_trial, 'Accuracy:', 100-MAPE) SearchResultsData=SearchResultsData.append(pd.DataFrame(data=[[TrialNumber, str(batch_size_trial)+'-'+str(epochs_trial), 100-MAPE]], columns=['TrialNumber', 'Parameters', 'Accuracy'] )) return(SearchResultsData) ###################################################### # Calling the function ResultsData=FunctionFindBestParams(X_train, y_train, X_test, y_test) |

Plotting the parameter trial results
|
1 2 |
%matplotlib inline ResultsData.plot(x='Parameters', y='Accuracy', figsize=(15,4), kind='line') |

This graph shows that the best set of parameters are batch_size=15 and epochs=5. Next step is to train the model with these parameters.
Training the ANN model with the best parameters
Using the best set of parameters found above, training the model again and predicting the prices on testing data.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# Fitting the ANN to the Training set model.fit(X_train, y_train ,batch_size = 15, epochs = 5, verbose=0) # Generating Predictions on testing data Predictions=model.predict(X_test) # Scaling the predicted Price data back to original price scale Predictions=TargetVarScalerFit.inverse_transform(Predictions) # Scaling the y_test Price data back to original price scale y_test_orig=TargetVarScalerFit.inverse_transform(y_test) # Scaling the test data back to original scale Test_Data=PredictorScalerFit.inverse_transform(X_test) TestingData=pd.DataFrame(data=Test_Data, columns=Predictors) TestingData['Price']=y_test_orig TestingData['PredictedPrice']=Predictions TestingData.head() |

Finding the accuracy of the model
Using the final trained model, now we are generating the prediction error for each row in testing data as the Absolute Percentage Error. Taking the average for all the rows is known as Mean Absolute Percentage Error(MAPE).
The accuracy is calculated as 100-MAPE.
|
1 2 3 4 5 6 |
# Computing the absolute percent error APE=100*(abs(TestingData['Price']-TestingData['PredictedPrice'])/TestingData['Price']) TestingData['APE']=APE print('The Accuracy of ANN model is:', 100-np.mean(APE)) TestingData.head() |

Why the accuracy comes different every time I train ANN?
Even when you use the same hyperparameters, the result will be slightly different for each run of ANN. This happens because the initial step for ANN is the random initialization of weights. So every time you run the code, there are different values that get assigned to each neuron as weights and bias, hence the final outcome also differs slightly.
Finding best hyperparameters using GridSearchCV.
Apart from the manual search method shown above, you can also use the Grid Search Cross-validation method present in the sklearn library to find the best parameters of ANN.
The below snippet defines some parameter values to try and finds the best combination out of it.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
# Function to generate Deep ANN model def make_regression_ann(Optimizer_trial): from keras.models import Sequential from keras.layers import Dense model = Sequential() model.add(Dense(units=5, input_dim=7, kernel_initializer='normal', activation='relu')) model.add(Dense(units=5, kernel_initializer='normal', activation='relu')) model.add(Dense(1, kernel_initializer='normal')) model.compile(loss='mean_squared_error', optimizer=Optimizer_trial) return model ########################################### from sklearn.model_selection import GridSearchCV from keras.wrappers.scikit_learn import KerasRegressor # Listing all the parameters to try Parameter_Trials={'batch_size':[10,20,30], 'epochs':[10,20], 'Optimizer_trial':['adam', 'rmsprop'] } # Creating the regression ANN model RegModel=KerasRegressor(make_regression_ann, verbose=0) ########################################### from sklearn.metrics import make_scorer # Defining a custom function to calculate accuracy def Accuracy_Score(orig,pred): MAPE = np.mean(100 * (np.abs(orig-pred)/orig)) print('#'*70,'Accuracy:', 100-MAPE) return(100-MAPE) custom_Scoring=make_scorer(Accuracy_Score, greater_is_better=True) ######################################### # Creating the Grid search space # See different scoring methods by using sklearn.metrics.SCORERS.keys() grid_search=GridSearchCV(estimator=RegModel, param_grid=Parameter_Trials, scoring=custom_Scoring, cv=5) ######################################### # Measuring how much time it took to find the best params import time StartTime=time.time() # Running Grid Search for different paramenters grid_search.fit(X,y, verbose=1) EndTime=time.time() print("########## Total Time Taken: ", round((EndTime-StartTime)/60), 'Minutes') print('### Printing Best parameters ###') grid_search.best_params_ |
Conclusion
This template can be used to fit the Deep Learning ANN regression model on any given dataset.
You can take the pre-processing steps of raw data from any of the case studies here.
Deep ANNs work great when you have a good amount of data available for learning. For small datasets with less than 50K records, I will recommend using the supervised ML models like Random Forests, Adaboosts, XGBoosts, etc.
The simple reason behind this is the high complexity and large computations of ANN. It is not worth it, if you can achieve the same accuracy with a faster and simpler model.
You look at deep learning ANNs only when you have a large amount of data available and the other algorithms are failing or do not fit for the task.
In the next post, I will show how to fit an ANN model for any classification dataset.

Thank you very much for this example. I will try to adapt your example with my data. I am trying to predict salinity in the river to early warning for tap water production in Thailand.
Hi Phakawat!
Very happy to see that this post has helped you in your work!
Keep it up 🙂
Hi Farukh,
Thanks very much for sharing your python codes and instructions for this case study how to use ANN for multiple variable regression.
I’ve tried to follow your instructions and run your py code. I have some issue with declaring the input parameter matrix X as I found this errors:
” X=CarPricesDataNumeric[Predictors].values
Traceback (most recent call last):
File “”, line 1, in
File “C:\Program Files\Python311\Lib\site-packages\pandas\core\frame.py”, line 3902, in __getitem__
indexer = self.columns._get_indexer_strict(key, “columns”)[1]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Program Files\Python311\Lib\site-packages\pandas\core\indexes\base.py”, line 6114, in _get_indexer_strict
self._raise_if_missing(keyarr, indexer, axis_name)
File “C:\Program Files\Python311\Lib\site-packages\pandas\core\indexes\base.py”, line 6178, in _raise_if_missing
raise KeyError(f”{not_found} not in index”)
KeyError: “[‘Age’] not in index”
Can you have how to fix this bug so that I could go on to test your ANN codes.
Many thanks and kind regards,
Nino Ng
Hi Nino,
Thank you for kind words!
It looks like Age column is missing from the input data. Can you just check if you have not dropped it in the previous steps
Regards,
Farukh Hashmi
Thank you for this its been really helpful!
Hi Katie,
Thank you for your kind words!
I am happy that it was useful for you
MAPE = np.mean(100 * (np.abs(y_test-model.predict(X_test))/y_test))
the above formula can lead to negative error, so I recommend to use the following code,
from sklearn.metrics import mean_absolute_percentage_error
MAPE = mean_absolute_percentage_error(y_test, model.predict(X_test))
Hi Ann,
You are correct! Hence, whenever we are looking at regression results, we make sure to check median APE as well, as some of the predictions are bound to be bad, hence generating a large error and making the accuracy value negative. However, when a client looks into the dashboard, they tend to appreciate simple percentage differences instead of ML related computations like MAE, RMSE, etc. The MAPE implementation from sklearn does some massaging to the output and will require us to educate the users. That was the rationale behind evaluating the model in the same terms as the clients would see it using simple percentage differences between original and prediction. I hope that helps!
Hi, thanks for the article. How would you handle predictors (columns) with categorical data? For example what if a column has countries and another one has sectors? Thanks!
Hi Andrea,
We will have to treat categorical variables and convert them to numeric depending upon if its ordinal or nominal.
See this case study for more details on this.
https://thinkingneuron.com/restaurant-rating-prediction-case-study-in-python/
Hi Farukh,
Thanks for sharing the article. I was trying it and got the following error:
cannot import name ‘mirrored_strategy_with_two_gpus_no_merge_call’ from ‘tensorflow.python.distribute.strategy_combinations’
I tried to search for some solutions on the internet but didn’t found any. Can you help with this?
I am using Python 3.9.7 (64 bit).
Thanks
Gill
Hi Gill,
It is very difficult to debug code like this, if you can share the screenshot with full error, I might be able to help.
Hallo FARUKH, thank you for your effort.
i implemented this Tamplete on a Dataset its name “Housing_Price” to predict House prices , which i downloaded from Kaggle.
everything is ok but unfortunetly i become a zero accuracy when i train the Model but i dont really know what is the problem?!
i will be Thankfull if you could answer my question
Hi Mohamad!
It is difficult to comment about your code error without seeing your code! Can you share the screenshot of the cell and code where you are getting the accuracy as zero, maybe then I can help.
without cross-validation, the validation result compromised
how to use cross-validation, please suggest
Thanks!
Hi Pradeep!
You can use the GridSearchCV option. It produces the avg results based on k-Fold CV.
Regards,
Farukh Hashmi
Mistake in the code… normalization should be done post train/test split. You have baised the test data.
Hi Rakesh,
Thank you for your input!
The testing data must be on the same level of encoding as of training data. Hence using the same fit object is necessary for standardisation/normalisation.
If you do separate normalisation of test data, the range will vary and hence the predictions will be incorrect, because the model didn’t get the input at the same level it was trained on.
Hope that helps!
Regards,
Farukh Hashmi
Thank you for your nice code,
However, I still don’t understand why and how are there 5 groups of results (0~4).
Hi Alice,
If I am understanding it correct. You are referring to the cross validation step. Since we are using cv=5. The data is sampled 5-times hence, for each iteration there is one accuracy value.
Hope that helps!
I mean the ANN results
Age
0 59.0 …
1 62.0 …
2 59.0 …
3 69.0 …
4 65.0 …
Thank you for your prompt reply,
Due to the usage of “.head()”, that prints only the first 5 rows. Similarly, adding “.tail()” fetches the final 5 rows. [.head() and .tail() by default fetch the first 5 and last 5 rows, but to fetch the first or last 5 columns, you need to mention “axis = 1” inside the bracket of head() or tail()]
(:
HI Sir, Thank you for the guidance. One thing, can we use Hyperopt instead of gridsearch? Do you have any suggestions on that or a guide? Thank you
Hi Arin,
Yes you can use Hyperopt!
Please read below article.
https://thinkingneuron.com/how-to-tune-hyperparameters-automatically-using-bayesian-optimization/
Dear Farukh Hashmi Thank you very much for your such a great effort. I apricate your efforts for this post and a comprehensive theoretical background in the video.
JazakaAllah Khair.
Thank you for the kind words Sohail!
Hi Farukh,
Thank you for the article but somehow I am unable to fit the X and Y to the grid search. After Epoch 1 runs successfully I get this error :
NotFittedError: All estimators failed to fit
Hi Sreyasi!
In the latest versions GridSearchCV is throwing such errors. Can you try Random SearchCV and see if it works?
broo can u help me in doing a code..
Without your video and example, I will be unable to achieve my research. I have already published in Water, MDPI (https://doi.org/10.3390/w14050741). Thank you so much I really appreciate your guidance.
This is great news!!
Keep up the great work. 🙂
Hi Farukh,
Thank you so much for your efforts,
i have one question:
During the training process the loss = NAN
”
Epoch 1/50
67/67 [==============================] – 0s 1ms/step – loss: nan
Epoch 2/50
67/67 [==============================] – 0s 1ms/step – loss: nan”
Could you help me please?
Hi Mostafa,
Is this happening for all the runs?
make sure your target variable does not contain any value that is zero. Because it may generate divide by zero issue or NANs
Regards,
Farukh Hashmi
hi Farukh! my data has already been split into training and testing data, what code should i write to reference these datas?
Hi Sachdev,
You can append train and test data to pass it for cross validation. Or simply train the model on train and validate the model on test data.
Regards,
Farukh Hashmi
Hi,
can you please tell me what kind of neural network this is? Is it a feedforward neural network or a CNN? Also can values of accuracy in the epoch calculating section surpass 100% and if so what does it mean for the model?
Hi Mike!
This is a Feed forward neural network.
The accuracy should stay within 100%, However when you use custom metric like MAPE, then you may see negative results if there are outliers in the errors.
Regards,
Farukh Hashmi
Would you please suggest me how to select number of units for each layer?
In my data input_dim=3.
Very helpful tutorial, please can you help with the neural network equation..?
Hi Godswill!
I have tried to explain the equation of a Neuron in the video.
https://youtu.be/i3crGbdElSw
Hope that helps!
Regards,
Farukh Hashmi
Very helpful post. After checking several website, lastly I succeed to fit my data with the given code. Can you help me regarding tuning the number of neurons and layers?
Hi Soumya,
You start with a smaller number for each and then keep increasing them and note accuracy after every change.
The idea is to find that sweet spot where you are getting highest accuracy with minimum number of neurons and layers. Because after a point you will see the testing accuracy decrease, that means model has started overfitting.
Always remember, every neuron you add is increasing one more equation for the overall model!
Hope this helps!
Regards,
Farukh Hashmi
Dear Farukh Hashmi, Thank you very much for your such a great article. I have a follow up question. Once you have the final best model ready, how do we apply it to a new dataset to predict the second hand car price?
Hi
Thank you for your kind words!
Please see this post and look at the deployment section.
https://thinkingneuron.com/car-price-prediction-case-study-in-python/
Regards
Farukh Hashmi
Thank you very much for this tutorial.
but I am confused. I have read in different place that the accuracy is not a good metric for regression. can you please help me to understand while you used accuracy?
Please also I would like to have an example using may be mean squared error or determination coefficient. also the kind of plot I can do to confirm my result.
thank you and sorry for too much questions
greeting all I got this code very helpful . can you tell how to get coefficients’ to write an empirical formula. how can I extend this in getting weight and biases.
Dear Farukh Hashmi,
Thank you for the article and video. It was very helpful.
May you please advise the reason for getting accuracy above 100?
2/2 [==============================] – 0s 0s/step
9 Parameters: batch_size: 15 – epochs: 5 Accuracy: 128.60392062417344
2/2 [==============================] – 0s 0s/step
5 Parameters: batch_size: 10 – epochs: 5 Accuracy: 137.93475685949863
Hi! I am getting an error when I run this that says “incompatible shapes: [##] vs. [##,%%]” (the ## is the same number, and the %% is a different number). Do you have any idea why this might be happening or how I can fix it?
Hi Farukh,
Your work is helping me a lot—many thanks. However, could you please help me on this issue?
I am trying to move from Matlab to Python, and I was wondering why you only split between
Train and Test. In Matlab, we are used to splitting between Train, Validate, and Test. The Validation
split helps to fine-tune the internal hyperparameters as I am sure you know. Why we cannot see this
in your Python Programs ? and if in the case it wasn’t necessary, can it be done and how ?
Many Thanks Again.