
Table of contents
- What is BERT?
- Causal Language Modeling
- DistilBERT and HuggingFace
- Sentiment Analysis on Tweets using BERT
Customer feedback is very important for every organization, and it is very valuable if it is honest!
Twitter is one of the best platforms to capture honest customer reviews and opinions.
If you want to learn how to pull tweets live from twitter, then look at the below post.
How to pull Tweets from Twitter using Python
In this post I will talk about the actions you take on that tweet text data which was collected.
The number one priority is to understand the mood of the customers by looking at their feedback text. Whether they are happy, sad, or angry! This is known as Sentiment Analysis.
There are many ways to perform sentiment analysis. Popular ones are the bag of words model and Textblob. In this post, I am going to show you how can you do sentiment analysis on a given text data using BERT.
What is BERT?
BERT stands for Bidirectional Encoder Representations from Transformers and it is a state-of-the-art machine learning model used for NLP tasks like text classification, sentiment analysis, text summarization, etc.
Okay… so what is Bidirectional? What are Encoder Representations? And what is Transformer??!!
Let’s trace it back one step at a time! There is a lot that happened before BERT. Each iteration improved the previous solutions.
To put the timeline in perspective. Below is the order in which things evolved.
RNN -> LSTM -> Encoder-Decoder -> Transformers-> BERT
First came the concept of Back Propagation Through Time(BPTT) in the Recurrent Neural Networks(RNN). This started a revolution in machine translation(e.g. French to English conversion). Because now we can learn lots of translation examples by using the numeric representation of words in the input and output sentences. It can be from any language, we can always find the numeric representation of these words, popular ones are Word2Vec, GloVe, etc.
The input sequence is a set of numbers representing the input text in English and the output sequence is a set of numbers representing the expected output text in Hindi.

Many such input and output pairs can be generated for learning the language translation from English to Hindi. The algorithm which can help us learn such data is known as Recurrent Neural Networks(RNN) or the Long Short Term Memory networks(LSTM) which is an improved version of RNNs. This type of learning algorithm is known as Sequence to Sequence(Seq2Seq) algorithms.

The issue with the RNN’s was the Vanishing Gradient problem or Exploding Gradient problem. Due to this, long-term dependencies of words were not learned properly. For example, if there is a sentence like “Ram is good, he works hard!” The use of “he” indicates the gender, and if there was a female name, then the “she” word would have been used. RNNs could not learn this kind of relationship. Hence, LSTM’s were invented with the addition of a memory pipeline to the RNN neurons. This allowed LSTM’s to ‘remember’ long-term dependencies in words by storing important data in the memory pipeline.

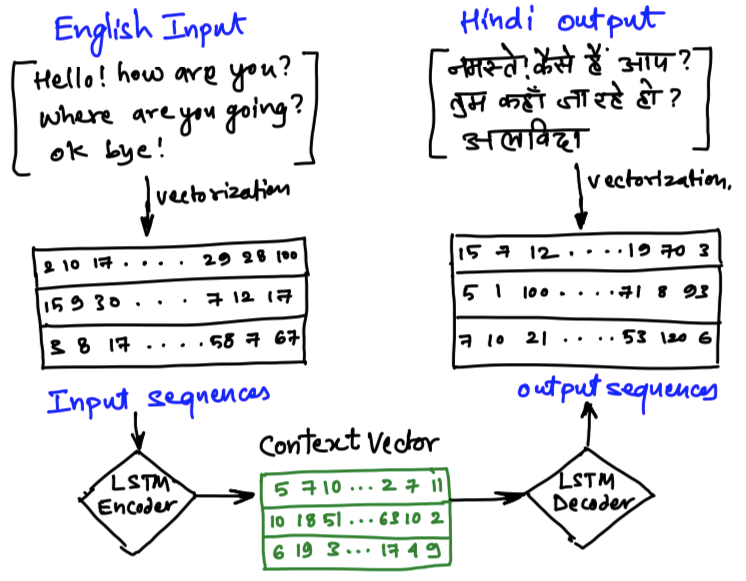
After this one more framework came into the picture, it was called Encoder-Decoder. The need to invent Encoder-Decoder was to address the issue of variable length of input and outputs. Because when you translate, you may give a small sentence or a large sentence. This can be handled better if all the inputs were converted to a fixed-length context vector.
Look at the below diagram. No matter what is the input size, it will be converted to a fixed-length vector by one LSTM network called the Encoder, because it is encoding the input to a pre-defined length of a numeric vector. This context vector acts as an input to another LSTM network called the Decoder. It will always get a fixed set of inputs in form of the context vector and learn it against the variable-length outputs.
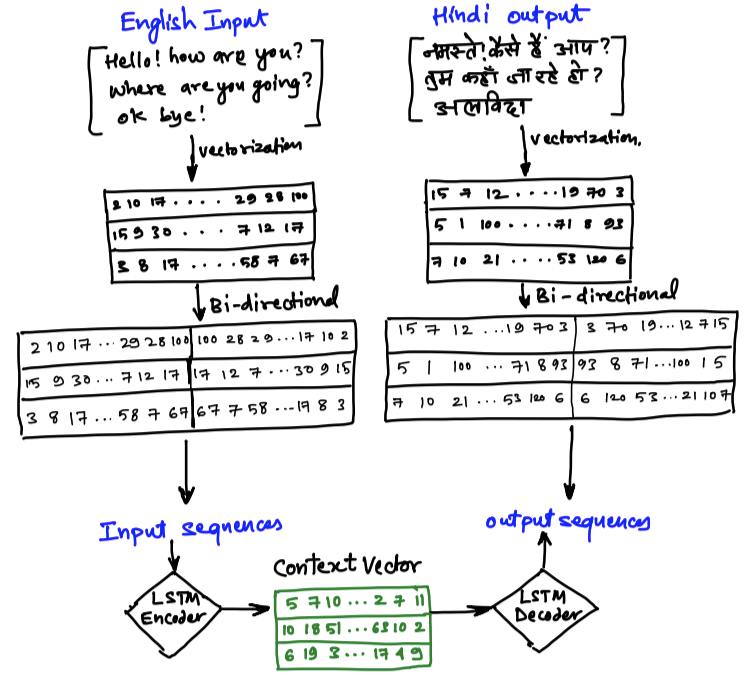
The learning of the sequences were unidirectional till now. It is understood from Left to Right. If we append the reverse of input to the original input and the reverse of output to the original output, then we will be learning the input and output from both directions. This is known as Bi-Directional encoder-decoder.
Life was good! and we thought we conquered the machine translation. Then, all of a sudden, the strict sequence processing of RNN/LSTM based encoder-decoder models hit us hard in the face and put us down 🙁
The issue with all the sequence learning frameworks was the inability of parallel processing, hence, learning large datasets was a big challenge. Then a new paper was released by the brilliant folks at Google which said “Attention is all you need!” The proposal was to discard RNN/CNN/LSTM and use a simple network with self-attention! Now, this enabled us to learn the input and output words in parallel! This allowed us to learn massive amounts of text data. This new technique was the famous “Transformer” architecture. Hence, a Transformer is an encoder-decoder mechanism with self-attention.
A Transformer is an encoder decoder mechanism with self attention.

Causal Language Modeling
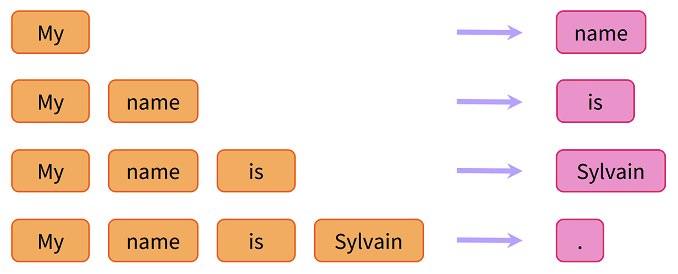
When we deal with Natural Language processing, there is always a lack of labeled data. Hence, there was a need to create a mechanism, where algorithms could generate the data for learning by themselves! We just have to provide the data to it. this is called Semi-Supervised Learning. For example, consider the sentence “My name is Sylvain.“
We can generate the below learning examples from one sentence. Each word is predicted by the last “n” words. This style of data generation is known as Language Modeling.

Now, imagine if we pass all the text in Wikipedia to such an algorithm or all the tweets in the world. Then learn these input and output using Transformers. What we will get as a result is a numeric vector for each of the words present in the dictionary!
These numeric vectors are nothing but the result of the encoder part of Transformer models which will learn such huge data. Now, this is similar to Word2Vec or GloVe where you try to represent each word as a numeric vector. The only change here is the way the data is learned and much better context retention between words.
These encoder representations from Transformers are shared and you can use them for any of your tasks, like sentiment analysis, text classification, text summarization, etc.
This is known as Transfer Learning! Since you cannot train such a huge amount of text data, it will require large GPU/TPU processors and multiple days to train the model.
Now… you can understand what is Bi-directional Encoder Representations from Transformers. It is BERT!
Using BERT architecture every company started creating their own version of BERT by using their own text data and called the results as they pleased! This is why you see so many names like ALBERT from Google Research, RoBERTa by Facebook, TinyBERT by Huawei, DistilBERT by HuggingFace, etc.

Look at the number of parameters in millions!! There are really big models. Which created another issue of usability by common folks like us! Hence, efforts were made to create smaller and lightweight language models. One such model is DistilBERT, shown encircled in the above diagram. This has the goodness of BERT but is much more faster and lighter.
DistilBERT model is from a company named HuggingFace. which is devoted to research in NLP. They have created a library called ‘transformers‘ which has a module called ‘pipeline‘. This allows you to perform a lot of NLP tasks out of the box! Although, if required you also can train the models on your specific data, but, looking at the performance of out the box models, I think it is not required for our current use case of sentiment analysis.
Transformers pipeline
The most basic object in the transformers library is the pipeline. It connects a model with its necessary preprocessing and post-processing steps, allowing us to directly input any text and get an intelligible answer.
Some of the currently available pipelines are listed below.
- feature-extraction (get the vector representation of a text)
- fill-mask
- ner (named entity recognition)
- question-answering
- sentiment-analysis
- summarization
- text-generation
- translation
- zero-shot-classification
More information: https://huggingface.co/course/chapter1/3?fw=pt
Sentiment Analysis
Let us use the above pipeline to generate sentiments on tweet texts.
You can download the tweets data for this case study here.
|
1 2 3 4 5 6 7 |
import pandas as pd import numpy as np # Reading the indigo tweets data IndigoTweets=pd.read_csv('Indigo Tweets.csv', encoding='latin') print(IndigoTweets.shape) IndigoTweets.head(10) |

Installing transformers library
|
1 2 3 4 5 |
# installing the library 'transformers' which contains BERT implementation !pip install transformers # installing the library tensorflow !pip install tensorflow |
Downloading Sentiment Analysis Model
Here we are downloading the pre-trained sentiment analysis model from the transformers’ pipeline module. We can just pass any text to it and it will the sentiment score. As simple as that!
|
1 2 3 4 5 |
# importing the pipeline module from transformers import pipeline # Downloading the sentiment analysis model SentimentClassifier = pipeline("sentiment-analysis") |

Sample Call using the Sentiment Classifier Function
Below is a sample call of the Sentiment Classifier function for three sentences, just to check the output format.
|
1 2 3 4 5 |
# Calling the sentiment analysis function for 3 sentences SentimentClassifier(["I hope we get all these concepts! Its killing the neurons of our brain", "We had a nice experience in this trip", "Houston we have a problem" ]) |

Now, we can write a function which will use these scores and return a final sentiment like positive, negative or neutral from the output label.
|
1 2 3 4 5 6 |
# Defining a function to call for the whole dataframe def FunctionBERTSentiment(inpText): return(SentimentClassifier(inpText)[0]['label']) # Calling the function FunctionBERTSentiment(inpText="Houston we have a problem") |

|
1 2 3 |
# Calling BERT based sentiment score function for every tweet IndigoTweets['Sentiment']=IndigoTweets['Tweets'].apply(FunctionBERTSentiment) IndigoTweets.head(10) |

|
1 2 3 4 5 6 7 8 9 10 11 |
# Visualizing the overall sentiment distribution import matplotlib.pyplot as plt fig, subPlot =plt.subplots(nrows=1, ncols=2, figsize=(10,4)) fig.suptitle("Sentiment analysis of Indigo Tweets") # Grouping the data GroupedData=IndigoTweets.groupby('Sentiment').size() # Creating the charts GroupedData.plot(kind='bar', ax=subPlot[0], color=['crimson', 'lightblue']) GroupedData.plot(kind='pie', ax=subPlot[1], colors=['crimson', 'lightblue']) |

Conclusion
Transfer learning is the way forward in NLP. It helps us leverage the research work done by big organizations like facebook and google. BERT is one such great example. It has improved the search results dramatically. Now when you google something, you get more relevant results due to BERT. You can read more about it here!
I hope this post was helpful for you to understand BERT and how can you use it for sentiment analysis. Consider sharing this with your friends to spread the knowledge and help me grow as well!

Useful information on sentiment analysis. I liked the way you explained how it is evolved to BERT.