
In the previous post, I discussed the major types of machine learning. In this post, I will discuss the popular supervised machine learning algorithms which are asked in the data science interviews.
I will also share the code to implement each one them in R/Python.
Table of Contents
- Overview
- Sample Datasets
- Linear Regression
- Logistic Regression
- Decision Tree
- Random Forest
- Adaboost
- XGBoost
- KNN
- SVM
Overview
In most of the IT projects, you will be able to find a use case for Supervised Machine learning. Because there will always be a need to predict a future number like sales, turnover, number of support tickets or the demand for a product, etc. This is when you will perform Regression.
Similarly, there will always be a need to classify records. e.g. If a home loan should be issued or not? What is the value of a customer (Silver, Gold, Platinum), is this insurance claim fraud or not? etc. This is when you will perform Classification
Supervised Machine Learning algorithms can be grouped into two categories (Regression and Classification) listed below. There are many statistical algorithms which are used for Supervised Machine Learning. I am listing some of the popular ones here which can be used to solve any given Regression or Classification problem with good accuracy.
Regression(Predicting a continuous number): Linear Regression, Decision Trees, Random Forests, XGboost, Adaboost.
Classification(Predicting a class): Logistic Regression, Decision Trees, Random Forests, XGboost Adaboost, KNN, SVM.

Supervised Machine Learning
As you can see some of the algorithms are suitable for regression as well as classification. The final choice is made by measuring the accuracy of the model.
When you are asked about any of the algorithms, try to use below flow while describing it.
- What is the core concept of the algorithm (Overview)?
- The Mathematical logic behind the algorithm.
- In which language(R/Python) you have implemented this algorithm
- What are the hyperparameters you tuned and the effect of these parameters?
- How do you measure its accuracy?
- Which type of use cases fit this algorithm/Why it was selected for your project.
Sample Datasets
I have used two simple datasets for regression and classification algorithms. I have written the code below to generate these in R and Python.
- Regression: This small dataset contains the weight and number of hours samples for random people who spend time at the Gym along with how many calories they consume in a day.
Target variable: Weight
Predictors: Hours, Calories

- Classification: This small dataset contains the loan approval history for various applicants based on their AGE, SALARY and CIBIL score.
Target variable: APPROVE_LOAN
Predictors: CIBIL, AGE, SALARY

Create sample datasets in R
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
#### Create Gym Data for regression in R #### # Generating Data Vectors Hours=c(1.0, 2.0, 2.5, 3.0, 3.5, 4.0, 5.0, 5.5, 6.0, 6.5) Calories=c(2500, 2000, 1900, 1850, 1600, 1500, 1500, 1600, 1700, 1500) Weight=c(95, 85, 83, 81, 80, 78, 77, 80, 75, 70) # Creating the sample dataframe GymData=data.frame(Hours, Calories, Weight) print(GymData) # Sampling | Splitting data into 70% for training 30% for testing TrainingSampleIndex=sample(1:nrow(GymData), size=0.7 * nrow(GymData) ) DataForMLTrain=GymData[TrainingSampleIndex, ] DataForMLTest=GymData[-TrainingSampleIndex, ] dim(DataForMLTrain) dim(DataForMLTest) ####################################################### #### Create Loan Data for classification in R #### # Generating Data Vectors CIBIL=c(480,480,480,490,500,510,550,560,560,570,590,600,600,600,610,630,630,660,700,740) AGE=c(28,42,29,30,27,34,24,34,25,34,30,33,22,25,32,29,30,29,32,28) SALARY=c(610000,140000,420000,420000,420000,190000,330000,160000,300000, 450000,140000,600000,400000,490000,120000,360000,480000,460000,470000,400000) APPROVE_LOAN=c("Yes","No","No","No","No","No","Yes","Yes","Yes","Yes","Yes", "Yes","Yes","Yes","Yes","Yes","Yes","Yes","Yes","Yes") LoanData=data.frame(CIBIL,AGE,SALARY,APPROVE_LOAN) print(LoanData) # Sampling | Splitting data into 70% for training 30% for testing TrainingSampleIndex=sample(1:nrow(LoanData), size=0.7 * nrow(LoanData) ) DataForMLTrain=LoanData[TrainingSampleIndex, ] DataForMLTest=LoanData[-TrainingSampleIndex, ] dim(DataForMLTrain) dim(DataForMLTest) |
Create sample datasets in Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
#### Create Gym Data for regression in Python #### import pandas as pd import numpy as np ColumnNames=['Hours','Calories', 'Weight'] DataValues=[[ 1.0, 2500, 95], [ 2.0, 2000, 85], [ 2.5, 1900, 83], [ 3.0, 1850, 81], [ 3.5, 1600, 80], [ 4.0, 1500, 78], [ 5.0, 1500, 77], [ 5.5, 1600, 80], [ 6.0, 1700, 75], [ 6.5, 1500, 70]] #Create the Data Frame GymData=pd.DataFrame(data=DataValues,columns=ColumnNames) GymData.head() #Separate Target Variable and Predictor Variables TargetVariable='Weight' Predictors=['Hours','Calories'] X=GymData[Predictors].values y=GymData[TargetVariable].values #Split the data into training and testing set from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) ################################################################### #### Create Loan Data for Classification in Python #### import pandas as pd import numpy as np ColumnNames=['CIBIL','AGE', 'SALARY', 'APPROVE_LOAN'] DataValues=[[480, 28, 610000, 'Yes'], [480, 42, 140000, 'No'], [480, 29, 420000, 'No'], [490, 30, 420000, 'No'], [500, 27, 420000, 'No'], [510, 34, 190000, 'No'], [550, 24, 330000, 'Yes'], [560, 34, 160000, 'Yes'], [560, 25, 300000, 'Yes'], [570, 34, 450000, 'Yes'], [590, 30, 140000, 'Yes'], [600, 33, 600000, 'Yes'], [600, 22, 400000, 'Yes'], [600, 25, 490000, 'Yes'], [610, 32, 120000, 'Yes'], [630, 29, 360000, 'Yes'], [630, 30, 480000, 'Yes'], [660, 29, 460000, 'Yes'], [700, 32, 470000, 'Yes'], [740, 28, 400000, 'Yes']] #Create the Data Frame LoanData=pd.DataFrame(data=DataValues,columns=ColumnNames) LoanData.head() #Separate Target Variable and Predictor Variables TargetVariable='APPROVE_LOAN' Predictors=['CIBIL','AGE', 'SALARY'] X=LoanData[Predictors].values y=LoanData[TargetVariable].values #Split the data into training and testing set from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) |
Let’s get started with the questions!
Q. Explain how the Linear Regression algorithm works?

Linear regression algorithm is based on the equation of a line (y= m * X + C).
The assumption is that the variables are related in a linear way.

In Machine Learning, the target variable is ‘y’ and the predictor is ‘X’.
The linear regression algorithm helps to find the best values of the coefficients ‘m’ and ‘C’ for given data using a cost function. One of the cost functions is known as the Sum of Squared Errors(SSE). There are many others like Root Mean Squared Error(RMSE), Mean of Squared Errors (MAE), log loss or Cross-Entropy loss, etc.
Example: Predict the weight of a person based on the number of hours spent at the gym and the amount of calories intake every day.
Target Variable: Weight
Predictors: Hours, Calories
Simple Linear Regression Equation: Weight = m* (Hours) + C
Multiple Linear Regression Equation: Weight = m1 * (Hours) + m2 * (Calories)+ C
For multiple linear regression, the algorithm finds the best values of the coefficients m1, m2, and C.
If there is one predictor then its called simple linear regression, if there are more than one predictors then it is called multiple linear regression.
Normal linear regression(Ordinary Least Square Regression) does not have any hyperparameters to tune.
If you are using regularization, then either Ridge or Lasso is used.
Regularization means reducing the effect of a variable in the equation by multiplying it by a very small coefficient. Hence, penalize that variable. This penalty can be given in two ways, first is Ridge and second is LASSO.
Ridge regression improves prediction error by shrinking large regression coefficients in order to reduce overfitting, but it does not perform variable selection and therefore does not help to make the model more interpretable. This is where LASSO comes into the picture.
Lasso(Least Absolute Shrinkage and Selection Operator) is able to improve the prediction accuracy and perform the variable selection by forcing certain coefficients(m1, m2, etc) to be set to zero, hence, choosing a simpler model that does not include those predictors.
Accuracy Measurement is done using Mean Absolute Percent Error Or Root Mean Squared Error.
Accuracy=100- MAPE or 100-RMSE.
Q. How to do linear regression in R?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
###### Linear Regression in R ####### Model_Reg=lm(formula= Weight ~ Hours+Calories,data=DataForMLTrain) # Measuring Goodness of Fit using R2 value on TRAINING DATA Orig=DataForMLTrain$Weight Pred=predict(Model_Reg, DataForMLTrain) R2= 1 - (sum((Orig-Pred)^2)/sum((Orig-mean(Orig))^2)) print(paste('R2 Value is:',round(R2,2))) # Predictions of model on Testing data DataForMLTest$Prediction=predict(Model_Reg, DataForMLTest) head(DataForMLTest) # Calculating the Absolute Percentage Error for each prediction in TESTING DATA LM_APE= 100 *(abs(DataForMLTest$Prediction - DataForMLTest$Weight)/DataForMLTest$Weight) print(paste('### Mean Accuracy of Linear Regression Model is: ', 100 - mean(LM_APE))) print(paste('### Median Accuracy of Linear Regression Model is: ', 100 - median(LM_APE))) |
Q. How to do linear regression in Python?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
###### Linear Regression in Python ####### import pandas as pd from sklearn.linear_model import LinearRegression RegModel = LinearRegression() #Printing all the parameters of Linear regression print(RegModel) #Creating the model on Training Data LREG=RegModel.fit(X_train,y_train) prediction=LREG.predict(X_test) from sklearn import metrics #Measuring Goodness of fit in Training data print('R2 Value:',metrics.r2_score(y_train, LREG.predict(X_train))) #Measuring accuracy on Testing Data print('Accuracy',100- (np.mean(np.abs((y_test - prediction) / y_test)) * 100)) #Printing some sample values of prediction TestingDataResults=pd.DataFrame(data=X_test, columns=Predictors) TestingDataResults[TargetVariable]=y_test TestingDataResults[('Predicted'+TargetVariable)]=prediction TestingDataResults.head() |
Q. Explain how Logistic Regression algorithm works?

Logistic Regression is used for predicting a category, specially the Binary categories(Yes/No , 0/1).
For example, whether to approve a loan or not (Yes/No)? Which group does this customer belong to (Silver/Gold/Platinum)? etc.
When there are only two outcomes in Target Variable it is known as Binomial Logistic Regression.
If there are more than two outcomes in Target Variable it is known as Multinomial Logistic Regression.
If the outcomes in Target Variable are ordinal and there is a natural ordering in the values (eg. Small<Medium<Large) then it is known as Ordinal Logistic Regression.

Logistic regression is based on logit function logit(x) = log(x / (1 – x))
The output is a value between 0 to 1. It is the probability of an event’s occurrence.
E.g. There is an 80% chance that the loan application is good, approve it.
The coefficients β0, β1, β2, β3… are found using Maximum Likelihood Estimation Technique. Basically, if the Target Variable’s value (y) is 1, then the probability of one “P(1)” should be as close to 1 as possible and the probability of zero “P(0)” should be as close to 0 as possible. Find those coefficients which satisfy both the conditions.
The Goodness of Fit (AIC and Deviance ):
These measures help to understand how good the model fits the data. Please note This is NOT the Accuracy of the model.
AIC The Akaike Information Criterion (AIC)
provides a method for assessing the quality
of your model through comparison of
related models. The number itself is not
meaningful. If you have more than one
model then you
should select the model that has the
smallest AIC.
The null deviance shows how well the
Target variable is predicted by a model that
includes only the intercept (grand mean).
The Residual deviance shows how well the target variable is predicted by a model that includes multiple independent predictors
Accuracy Measurement is done using f1-Score/Precision/Recall/ROC/AUC.
Q. How to do Logistic Regression in R?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
###### Logistic Regression in R ####### # Creating the model on TRAINING data Model_LR=glm(APPROVE_LOAN~CIBIL+AGE+SALARY, data=DataForMLTrain, family='binomial') # Checking Accuracy of model on Testing data DataForMLTest$Prediction=predict(Model_LR, DataForMLTest) head(DataForMLTest) #Creating the Confusion Matrix to calculate overall accuracy, precision and recall on TESTING data library(caret) AccuracyResults=confusionMatrix(DataForMLTest$Prediction, DataForMLTest$APPROVE_LOAN, mode = "prec_recall") #Since AccuracyResults is a list of multiple items, fetching useful components only AccuracyResults[['table']] AccuracyResults[['byClass']] print(paste('### Overall Accuracy of Logistic Regression Model is: ', round(100 * AccuracyResults[['overall']][1]) , '%')) |
Q. How to do Logistic Regression in Python?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
###### Logistic Regression in Python ####### import pandas as pd from sklearn.linear_model import LogisticRegression #choose parameter Penalty='l1' or C=1 clf = LogisticRegression(C=1,penalty='l1') #Printing all the parameters of logistic regression print(clf) #Creating the model on Training Data LOG=clf.fit(X_train,y_train) prediction=LOG.predict(X_test) #Measuring accuracy on Testing Data from sklearn import metrics print(metrics.classification_report(y_test, prediction)) print(metrics.confusion_matrix(y_test, prediction)) #Printing some sample values of prediction TestingDataResults=pd.DataFrame(data=X_test, columns=Predictors) TestingDataResults['TargetColumn']=y_test TestingDataResults['Prediction']=prediction TestingDataResults.head() |
Q. Explain how the Decision Tree algorithm works?
Decision Trees are suitable for both Regression as well as Classification use cases.
Below Video explains how Decision Trees work for Regression use cases.

The below video explains how Decision Trees work for Classification.

- Decision trees select the best predictor out of all available predictors by measuring its efficiency using either Entropy, Information gain or Gini index
- Basic idea is to choose that predictor which helps to slice the data into two parts in such a way that each part contains similar values of the target variable
- This activity creates a “root node”. Basically the first ‘if-statement’ to check to make decisions
- keep repeating the same activity with both the slices of data until no further splits can be made.
Consider below example where Loan approval historical data is provided.
Target Variable: APPROVE_LOAN
Predictors: CIBIL, AGE, SALARY
Now, we need to find a “rule” or set of rules using this data which can help to make the decision about a new loan application.

The Decision Tree algorithm will try to find the best splitter of data.
Basically, out of AGE, SALARY and CIBIL score of a loan applicant, which predictor “segregates” all the “Yes” cases together and all the “No” cases together?
Since this is a simple data, we can see this with basic data analysis that “All loans are approved if the CIBIL score is more than 550”
Hence, by learning from historical data, we can formulate a rule. IF CIBIL>550 THEN Approve a loan ELSE reject it.

If we pass this data to the Decision Tree algorithm, it finds out this rule by itself and a decision node (IF-ELSE statement) is created as shown below.

If the data is not simple, then the same procedure is repeated until no further splits can be made.

Q. How to create a Decision Tree for Regression in R?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
###### CTREE single Decision Tree REGRESSION ####### library(party) Model_CTREE=ctree(formula= Weight ~ Hours+Calories,data=DataForMLTrain) # Measuring Goodness of Fit using R2 value on TRAINING DATA Orig=DataForMLTrain$Weight Pred=predict(Model_CTREE, DataForMLTrain) R2= 1 - (sum((Orig-Pred)^2)/sum((Orig-mean(Orig))^2)) print(paste('R2 Value is:',round(R2,4))) # Predictions of model on Testing data DataForMLTest$Prediction=predict(Model_CTREE, DataForMLTest) head(DataForMLTest) # Calculating the Absolute Percentage Error for each prediction in TESTING DATA LM_APE= 100 *(abs(DataForMLTest$Prediction -DataForMLTest$Weight)/DataForMLTest$Weight) print(paste('### Mean Accuracy of Decision Tree Model is: ', 100 - mean(LM_APE))) print(paste('### Median Accuracy of Decision Tree Model is: ', 100 -median(LM_APE))) |
Q. How to create a Decision Tree for Classification in R?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
###### CTREE single Decision Tree CLASSIFICATION in R ####### # Creating the model on TRAINING data library(party) Model_RPART=ctree(APPROVE_LOAN~CIBIL+AGE+SALARY, data=DataForMLTrain) # Checking Accuracy of model on Testing data DataForMLTest$Prediction=predict(Model_RPART, DataForMLTest) head(DataForMLTest) # Creating the Confusion Matrix to calculate overall accuracy, precision and recall on TESTING data library(caret) AccuracyResults=confusionMatrix(DataForMLTest$Prediction, DataForMLTest$APPROVE_LOAN, mode = "prec_recall") # Since AccuracyResults is a list of multiple items, fetching useful components only AccuracyResults[['table']] AccuracyResults[['byClass']] print(paste('### Overall Accuracy of Decision Tree Model is: ', round(100 * AccuracyResults[['overall']][1]) , '%')) |
Q. How to create a Decision Tree for Regression in Python?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
###### Single Decision Tree Regression in Python ####### from sklearn import tree #choose from different tunable hyper parameters RegModel = tree.DecisionTreeRegressor(max_depth=3,criterion='mse') #Printing all the parameters of Decision Tree print(RegModel) #Creating the model on Training Data DTree=RegModel.fit(X_train,y_train) prediction=DTree.predict(X_test) #Measuring Goodness of fit in Training data from sklearn import metrics print('R2 Value:',metrics.r2_score(y_train, DTree.predict(X_train))) #Measuring accuracy on Testing Data print('Accuracy',100- (np.mean(np.abs((y_test - prediction) / y_test)) * 100)) #Plotting the feature importance for Top 10 most important columns %matplotlib inline feature_importances = pd.Series(DTree.feature_importances_, index=Predictors) feature_importances.nlargest(10).plot(kind='barh') #Printing some sample values of prediction TestingDataResults=pd.DataFrame(data=X_test, columns=Predictors) TestingDataResults[TargetVariable]=y_test TestingDataResults[('Predicted'+TargetVariable)]=prediction TestingDataResults.head() |
Q. How to create a Decision Tree for Classification in Python?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
###### Single Decision Tree CLASSIFICATION in Python ####### import pandas as pd from sklearn import tree #choose from different tunable hyper parameters clf = tree.DecisionTreeClassifier(max_depth=3,criterion='entropy') #Printing all the parameters of Decision Trees print(clf) #Creating the model on Training Data DTree=clf.fit(X_train,y_train) prediction=DTree.predict(X_test) #Measuring accuracy on Testing Data from sklearn import metrics print(metrics.classification_report(y_test, prediction)) print(metrics.confusion_matrix(y_test, prediction)) #Plotting the feature importance for Top 10 most important columns %matplotlib inline feature_importances = pd.Series(DTree.feature_importances_, index=Predictors) feature_importances.nlargest(10).plot(kind='barh') #Printing some sample values of prediction TestingDataResults=pd.DataFrame(data=X_test, columns=Predictors) TestingDataResults['TargetColumn']=y_test TestingDataResults['Prediction']=prediction TestingDataResults.head() |
Q. Explain how the Random Forest algorithm works?
Random Forests are suitable for both Regression as well as Classification use cases.


Random forests are basically multiple decision trees put together. This is also known as bagging
To create a Random Forest predictive model, the below steps are followed.
- Take some random rows from the data, let’s say 80% of all the rows randomly selected.
Hence every time selecting some different set of rows. - Take some random columns from the above data, let’s say 50% of all the columns randomly selected.
Hence every time selecting some different set of columns. - Create a decision tree using the above data.
- Repeat steps 1 to 3 for n number of times (Number of trees). n could be any number like 10 or 50 or 500 etc. (This is known as bagging)
- Combine the predictions from each of the trees to get a final answer.
In the case of Regression, the final answer is the average of predictions made by all trees.
In the case of Classification, the final answer is the mode(majority vote) of predictions made by all trees.
These steps ensure that every possible predictor gets a fair chance in the process.
Because we limit the columns used for each tree.
Also, there is very less bias in the model because we select some different set of random rows for each tree.
This above procedure helps to get good accuracy out of the box!
Consider below dataset with 20 records. The target variable is APPROVE_LOAN and predictors are CIBIL, AGE, and SALARY.

The first step is to create smaller samples of the above data by choosing a few random rows and predictor columns while always keeping the target variable in the sample. The number of predictor columns being chosen can be controlled using the parameter “max_features” by default it is the square root of the total number of predictor columns.
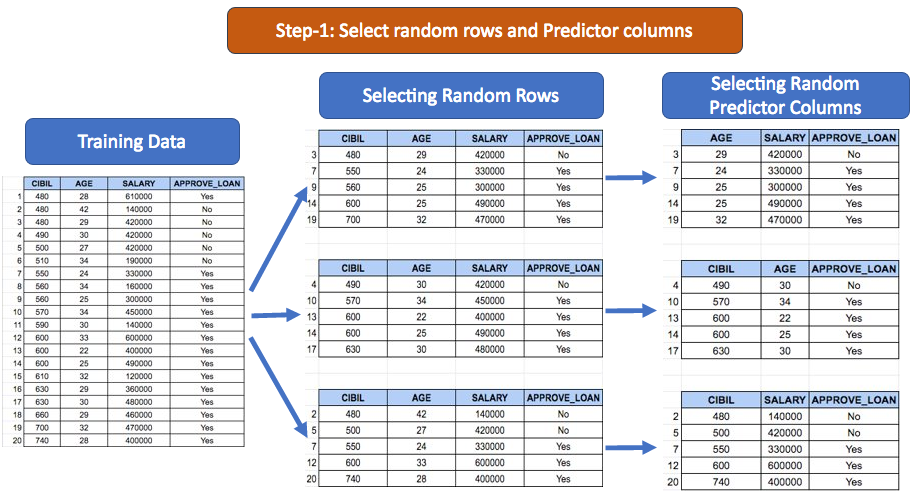
APPROVE_LOAN is the target variable, hence it will always be present
The second step is to create independent decision trees on each of the smaller datasets created above and combine the predictions from all of them in the below example, the number of trees (parameter n_estimators) is equal to 3.
The final prediction is the average of all predictions in case of regression and the majority vote in case of classification.

Q. How to create a Random Forest for Regression in R?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
###### Random Forest Regression in R ####### library(randomForest) Model_RF=randomForest(formula=Weight ~ Hours+Calories,data=DataForMLTrain,ntree=10) # Measuring Goodness of Fit using R2 value on TRAINING DATA Orig=DataForMLTrain$Weight Pred=predict(Model_RF, DataForMLTrain) R2= 1 - (sum((Orig-Pred)^2)/sum((Orig-mean(Orig))^2)) print(paste('R2 Value is:',round(R2,4))) # Predictions of model on Testing data DataForMLTest$Prediction=predict(Model_RF, DataForMLTest) head(DataForMLTest) # Calculating the Absolute Percentage Error for each prediction in TESTING DATA LM_APE= 100 *(abs(DataForMLTest$Prediction -DataForMLTest$Weight)/DataForMLTest$Weight) print(paste('### Mean Accuracy of Random Forest Model is: ', 100 - mean(LM_APE))) print(paste('### Median Accuracy of Random Forest Model is: ', 100 -median(LM_APE))) |
Q. How to create a Random Forest for Classification in R?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
###### Random Forest Classification in R ####### # Creating the model on TRAINING data library(randomForest) Model_RF=randomForest(APPROVE_LOAN~CIBIL+AGE+SALARY, data=DataForMLTrain, ntree=10) # Checking Accuracy of model on Testing data DataForMLTest$Prediction=predict(Model_RF, DataForMLTest) head(DataForMLTest) # Creating the Confusion Matrix to calculate overall accuracy, precision and recall on TESTING data library(caret) AccuracyResults=confusionMatrix(DataForMLTest$Prediction,DataForMLTest$APPROVE_LOAN, mode = "prec_recall") # Since AccuracyResults is a list of multiple items, fetching useful components only AccuracyResults[['table']] AccuracyResults[['byClass']] print(paste('### Overall Accuracy of Random Forest Model is: ', round(100 * AccuracyResults[['overall']][1]) , '%')) |
Q. How to create a Random Forest for Regression in Python?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
###### Random Forest Regression in Python ####### from sklearn.ensemble import RandomForestRegressor RegModel = RandomForestRegressor(n_estimators=100,criterion='mse') #Printing all the parameters of Random Forest print(RegModel) #Creating the model on Training Data RF=RegModel.fit(X_train,y_train) prediction=RF.predict(X_test) #Measuring Goodness of fit in Training data from sklearn import metrics print('R2 Value:',metrics.r2_score(y_train, RF.predict(X_train))) #Measuring accuracy on Testing Data print('Accuracy',100- (np.mean(np.abs((y_test - prediction) / y_test)) * 100)) #Plotting the feature importance for Top 10 most important columns %matplotlib inline feature_importances = pd.Series(RF.feature_importances_, index=Predictors) feature_importances.nlargest(10).plot(kind='barh') #Printing some sample values of prediction TestingDataResults=pd.DataFrame(data=X_test, columns=Predictors) TestingDataResults[TargetVariable]=y_test TestingDataResults[('Predicted'+TargetVariable)]=prediction TestingDataResults.head() |
Q. How to create a Random Forest for Classification in Python?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
###### Random Forest Classification in Python ####### #Random Forest (Bagging of multiple Decision Trees) from sklearn.ensemble import RandomForestClassifier clf = RandomForestClassifier(n_estimators=100,criterion='gini') #Printing all the parameters of Random Forest print(clf) #Creating the model on Training Data RF=clf.fit(X_train,y_train) prediction=RF.predict(X_test) #Measuring accuracy on Testing Data from sklearn import metrics print(metrics.classification_report(y_test, prediction)) print(metrics.confusion_matrix(y_test, prediction)) #Plotting the feature importance for Top 10 most important columns %matplotlib inline feature_importances = pd.Series(RF.feature_importances_, index=Predictors) feature_importances.nlargest(10).plot(kind='barh') #Printing some sample values of prediction TestingDataResults=pd.DataFrame(data=X_test, columns=Predictors) TestingDataResults['TargetColumn']=y_test TestingDataResults['Prediction']=prediction TestingDataResults.head() |
Q. Explain how the Adaboost algorithm works?
Adaboost is the short form for adaptive boosting.
It is an algorithm which ensembles(combines) multiple simple predictive models also known as weak learners to generate a final strong model.


Adaboost algorithm ensembles(combines) multiple simple predictive models also known as weak learners to generate a final strong model.
A decision tree with one level, also known as decision stumps is the most popular weak learner algorithm used in AdaBoost
These are called stumps because these are so simple that when you plot them you just a line (stump!)

Look at the image, here D1 is a decision stump.
Anything which is on the left side of D1 will be classified as positive (+) and anything which is on the right side will be classified as negative (-)
You can observe that it is not very efficient, because there are some positive values on the right side as well.

This is why multiple stumps are combined to create a final model which does a better job of classification
Adaboost is suitable for binary classification problems, however, you can use it for multi-class classification or regression as well.
The basic idea behind Adaboost is Boosting. It works with below listed steps
- Create a first predictive model on original data
- Create a second predictive model which corrects the mistakes of the first model
- Create a third predictive model which corrects the mistakes of the second model
- Keep creating more models until 100% accuracy is achieved OR the max number of iterations(number of trees) is reached
Adaboost take the general concept of boosting and adds a twist to it by assigning weights to data and models.
Adaboost take this general concept of boosting and adds a twist to it by assigning weights to data and models. Below listed steps describe the working of Adaboost.
- Take the original training data and assign a weight of 1/n to all rows. (n=total number of rows in Training data)
- Randomly select a subset of rows from the original data and create a predictive model(decision stump)
- Generate predictions on the above subset using the above predictive model
- Update the weights in the original data. Give higher weights to those rows where the prediction was incorrect, and give lesser weights to those rows where the prediction was correct. Give the current model higher weight if it is accurate, otherwise, give it less weight
- Select the rows from original data based on weights. Those with higher weights get selected first.
- These rows signify the mistakes by the previous predictive model.
- Create a predictive model on the above data.
- Repeat steps 3-6 until 100% accuracy is achieved OR the max number of iterations (number of trees) is reached
- The final prediction is the weighted average of all predictions made by different models created above.
Below flowchart visualizes the above-listed steps for Adaboost.

Q. How to create Adaboost for Regression in R?
There is no stable open-source version of Adaboost implementation for Regression in R language as of now.
Q. How to create Adaboost for Classification in R?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
###### Adaboost Classification in R ####### # Creating the model on TRAINING data library(caret) Model_ADA=train(APPROVE_LOAN ~CIBIL+AGE+SALARY, data=DataForMLTrain, method='adaboost') # Checking Accuracy of model on Testing data DataForMLTest$Prediction=predict(Model_ADA, DataForMLTest) head(DataForMLTest) # Creating the Confusion Matrix to calculate overall accuracy, precision and recall on TESTING data AccuracyResults=confusionMatrix(DataForMLTest$Prediction, DataForMLTest$APPROVE_LOAN, mode = "prec_recall") # Since AccuracyResults is a list of multiple items, fetching useful components only AccuracyResults[['table']] AccuracyResults[['byClass']] print(paste('### Overall Accuracy of ADABOOST Model is: ', round(100 * AccuracyResults[['overall']][1]) , '%')) |
Q. How to create Adaboost for Regression in Python?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
###### Adaboost Regression in Python ####### from sklearn.ensemble import AdaBoostRegressor from sklearn.tree import DecisionTreeRegressor #Choosing Decision Tree with 1 level as the weak learner DTR=DecisionTreeRegressor(max_depth=1) RegModel = AdaBoostRegressor(n_estimators=50, base_estimator=DTR ,learning_rate=1) #Printing all the parameters of Adaboost print(RegModel) #Creating the model on Training Data AB=RegModel.fit(X_train,y_train) prediction=AB.predict(X_test) #Measuring Goodness of fit in Training data from sklearn import metrics print('R2 Value:',metrics.r2_score(y_train, AB.predict(X_train))) #Measuring accuracy on Testing Data print('Accuracy',100- (np.mean(np.abs((y_test - prediction) / y_test)) * 100)) #Plotting the feature importance for Top 10 most important columns %matplotlib inline feature_importances = pd.Series(AB.feature_importances_, index=Predictors) feature_importances.nlargest(10).plot(kind='barh') #Printing some sample values of prediction TestingDataResults=pd.DataFrame(data=X_test, columns=Predictors) TestingDataResults[TargetVariable]=y_test TestingDataResults[('Predicted'+TargetVariable)]=prediction TestingDataResults.head() |
Q. How to create Adaboost for Classification in Python?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
###### Adaboost Classification in Python ####### import pandas as pd from sklearn.ensemble import AdaBoostClassifier from sklearn.tree import DecisionTreeClassifier #Choosing Decision Tree with 1 level as the weak learner DTC=DecisionTreeClassifier(max_depth=1) clf = AdaBoostClassifier(n_estimators=50, base_estimator=DTC ,learning_rate=1) #Printing all the parameters of Adaboost print(clf) #Creating the model on Training Data AB=clf.fit(X_train,y_train) prediction=AB.predict(X_test) #Measuring accuracy on Testing Data from sklearn import metrics print(metrics.classification_report(y_test, prediction)) print(metrics.confusion_matrix(y_test, prediction)) #Plotting the feature importance for Top 10 most important columns %matplotlib inline feature_importances = pd.Series(AB.feature_importances_, index=Predictors) feature_importances.nlargest(10).plot(kind='barh') #Printing some sample values of prediction TestingDataResults=pd.DataFrame(data=X_test, columns=Predictors) TestingDataResults['TargetColumn']=y_test TestingDataResults['Prediction']=prediction TestingDataResults.head() |
Q. Explain how the XGBoost algorithm works?
XGboost is the short form for Xtreme Gradient Boosting.
It is one of the most popular algorithms in machine learning universe. It is used by winners at most of the hackathons!
The reason for its popularity is listed below
- Handles large datasets with ease
- Trains very fast
- High accuracy for most of the datasets


The basic logic behind XGboost is Boosting.
Let us quickly revise how boosting works in general.
- Create a Predictive model M1.
- Create another Predictive model M2 which corrects the mistakes of the previous model M1. Hence M2 is the boosted version of M1.
- Create another Predictive model M3 which corrects the mistakes of the previous model M2.
- Keep repeating the process until the model is 100% accurate OR the maximum number of allowed iteration(number of trees) is reached.
The unique thing about XGBoost is how exactly it corrects the mistakes of the previous model.
The key differentiation about XGB is how exactly it corrects the mistakes of the previous model. In previous algorithm Adaboost, I discussed how it gives higher weights to the incorrectly predicted rows, and the next model focuses to reduce that.
In XGboost, the approach is focussed on reducing the error gradient (Mistakes of the previous model).
XGboost works with below-listed steps.

- Create a predictive model M1 on full Training data with the target variable “y”. (Notice that there is no random sampling here. XGBoost uses full training data.)
- Find the difference between the values of the original target variable “y” and predicted target variable “y1” as “e1 = y – y1”
- Create another predictive model M2 with the target variable as e1 which is “y – y1”. i.e. the gradient of the mistakes by previous model M1.
- Find the difference between the values of the target variable “y-y1” and predicted target variable “y2” as “e2 = y – y1 -y2”
- Create another predictive model M3 with the target variable as e2 which is “y – y1 -y2”. i.e. the gradient of the mistakes by previous model M2.
- Keep repeating these steps until the error becomes zero OR the maximum number of iterations is reached.
- The final model will exhibit the least amount of error and hence it will provide the maximum accuracy by learning from the mistakes of all previous models.
- The final prediction will be the sum of the predictions from all models. y_final = y1 + y2 + y3 …
This seems misleading at once but if you observe closely the Biggest value is y1 and all other values are adjustments to the y1 since these are the predictions for the errors and not the original target variable “y”.
Hence, the sum of all makes it more accurate since every next model tries to minimize the errors made by the previous model.
This is why XGboost is also known as an additive model since you keep adding weak learner models on top of the first one and in the end, you get a strong predictive model.
Xgboost keeps adding weak learner models on top of the first model and in the end, you get a strong predictive model.
Q. How to create XGBoost for Regression in R?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
###### Xgboost Regression in R ####### # Performing sampling again to create a fresh copy for XGBOOST # Sampling | Splitting data into 70% for training 30% for testing TrainingSampleIndex=sample(1:nrow(GymData), size=0.7 * nrow(GymData) ) DataForMLTrain=GymData[TrainingSampleIndex, ] DataForMLTest=GymData[-TrainingSampleIndex, ] dim(DataForMLTrain) dim(DataForMLTest) # XGBOOST requires data input in matrix format # XGBOOST works only on Numeric data so its mandatory to convert every factor PREDICTOR to numeric # Using Dummy variables library(dummies) DataForMLTrainDummy=dummy.data.frame(DataForMLTrain, sep='_', drop=F) DataForMLTestDummy=dummy.data.frame(DataForMLTest, sep='_', drop=F) # Making Sure the Datatype is numeric for each column DataForMLTrainDummy=sapply(DataForMLTrainDummy,as.numeric) DataForMLTestDummy=sapply(DataForMLTestDummy,as.numeric) # Choosing all other colums except target variable PredictorDataForTraining <- data.matrix(DataForMLTrainDummy[, -3]) PredictorDataForTesting <- data.matrix(DataForMLTestDummy[, -3]) # Choosing only the TargetVariable from data TargetVariableForTraining<- data.matrix(DataForMLTrainDummy[, 3]) # Training the XGboost model in Training data Model_XGB=xgboost(data=PredictorDataForTraining, label=TargetVariableForTraining, eta = 0.02, max_depth = 100 ,nround=1000, subsample=0.95) # Measuring Goodness of Fit using R2 value on TRAINING DATA Orig=DataForMLTrain$Weight Pred=predict(Model_XGB, PredictorDataForTraining) R2= 1 - (sum((Orig-Pred)^2)/sum((Orig-mean(Orig))^2)) print(paste('R2 Value is:',round(R2,4))) # Predictions of model on Testing data DataForMLTest$Prediction=predict(Model_XGB, PredictorDataForTesting) head(DataForMLTest) # Calculating the Absolute Percentage Error for each prediction in TESTING DATA LM_APE= 100 *(abs(DataForMLTest$Prediction - DataForMLTest$Weight)/DataForMLTest$Weight) print(paste('### Mean Accuracy of XGBOOST Model is: ', 100 - mean(LM_APE))) print(paste('### Median Accuracy of XGBOOST Model is: ', 100 - median(LM_APE))) |
Q. How to create XGBoost for Classification in R?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
###### Xgboost Classification in R ####### library(xgboost) # Performing sampling again to create a fresh copy for XGBOOST # Sampling | Splitting data into 70% for training 30% for testing TrainingSampleIndex=sample(1:nrow(LoanData), size=0.7 * nrow(LoanData) ) DataForMLTrain=LoanData[TrainingSampleIndex, ] DataForMLTest=LoanData[-TrainingSampleIndex, ] dim(DataForMLTrain) dim(DataForMLTest) # XGBOOST requires data input in matrix format # XGBOOST works only on Numeric data so its mandatory to convert every factor PREDICTOR to numeric # Using Dummy variables library(dummies) DataForMLTrainDummy=dummy.data.frame(DataForMLTrain[,-4], sep='_', drop=F) DataForMLTestDummy=dummy.data.frame(DataForMLTest[, -4], sep='_', drop=F) PredictorDataForTraining <- data.matrix(DataForMLTrainDummy[, -4]) PredictorDataForTesting <- data.matrix(DataForMLTestDummy[, -4]) head(PredictorDataForTraining) # Choosing only the TargetVariable from data TargetVariableForTraining<- DataForMLTrain[, 4] numberOfClasses=length(unique(TargetVariableForTraining)) head(TargetVariableForTraining) table(TargetVariableForTraining) # The XGBoost algorithm requires that the class values must start at 0 and increase sequentially to the maximum number of # classes. This is a bit of an inconvenience as you need to keep track of what name goes with which number. # Also, you need to be very careful when you add or remove a 1 to go from the zero based labels to the 1 based labels. # Converting all factor values to numeric values TargetVariableForTraining=as.numeric(TargetVariableForTraining) table(TargetVariableForTraining) # Subtracting 1 to start class values from 0 # Make sure you note down what number represents which factor values TargetVariableForTraining=TargetVariableForTraining-1 table(TargetVariableForTraining) # Converting to Data Matrix format TargetVariableForTraining=data.matrix(TargetVariableForTraining) xgb_params <- list("objective" = "multi:softmax","eval_metric" = "mlogloss","num_class" = numberOfClasses) # Creating the model on TRAINING data Model_XGB=xgboost(data=PredictorDataForTraining, label=TargetVariableForTraining, nrounds=10, params=xgb_params) # Checking Accuracy of model on Testing data DataForMLTest$Prediction=predict(Model_XGB, PredictorDataForTesting) head(DataForMLTest) # checking the training data to see the representation of each class NumberRepresentation=as.numeric(names(table(TargetVariableForTraining))) CharacterRepresentation=names(table(DataForMLTrain[, 4])) ValuesMapping=data.frame(NumberRepresentation,CharacterRepresentation) print(ValuesMapping) # Replacing all numbers with their character classes for(i in 1:nrow(ValuesMapping)){ DataForMLTest$Prediction=gsub(ValuesMapping[i,1],ValuesMapping[i,2],DataForMLTest$Prediction) } DataForMLTest$Prediction=as.factor(DataForMLTest$Prediction) head(DataForMLTest) # Creating the Confusion Matrix to calculate overall accuracy, precision and recall on TESTING data library(caret) AccuracyResults=confusionMatrix(DataForMLTest$Prediction, DataForMLTest$APPROVE_LOAN, mode = "prec_recall") # Since AccuracyResults is a list of multiple items, fetching useful components only AccuracyResults[['table']] AccuracyResults[['byClass']] print(paste('### Overall Accuracy of XGBOOST Model is: ', round(100 * AccuracyResults[['overall']][1]) , '%')) |
Q. How to create XGBoost for Regression in Python?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
###### Xgboost Regression in Python ####### from xgboost import XGBRegressor RegModel=XGBRegressor(max_depth=3, learning_rate=0.1, n_estimators=500, objective='reg:linear', booster='gbtree') #Printing all the parameters of XGBoost print(RegModel) #Creating the model on Training Data XGB=RegModel.fit(X_train,y_train) prediction=XGB.predict(X_test) #Measuring Goodness of fit in Training data from sklearn import metrics print('R2 Value:',metrics.r2_score(y_train, XGB.predict(X_train))) #Measuring accuracy on Testing Data print('Accuracy',100- (np.mean(np.abs((y_test - prediction) / y_test)) * 100)) #Plotting the feature importance for Top 10 most important columns %matplotlib inline feature_importances = pd.Series(XGB.feature_importances_, index=Predictors) feature_importances.nlargest(10).plot(kind='barh') #Printing some sample values of prediction TestingDataResults=pd.DataFrame(data=X_test, columns=Predictors) TestingDataResults[TargetVariable]=y_test TestingDataResults[('Predicted'+TargetVariable)]=prediction TestingDataResults.head() |
Q. How to create XGBoost for Classification in Python?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
###### Xgboost Classification in Python ####### import pandas as pd from xgboost import XGBClassifier clf=XGBClassifier(max_depth=3, learning_rate=0.1, n_estimators=500, objective='binary:logistic', booster='gbtree') #Printing all the parameters of XGBoost print(clf) #Creating the model on Training Data XGB=clf.fit(X_train,y_train) prediction=XGB.predict(X_test) #Measuring accuracy on Testing Data from sklearn import metrics print(metrics.classification_report(y_test, prediction)) print(metrics.confusion_matrix(y_test, prediction)) #Plotting the feature importance for Top 10 most important columns %matplotlib inline feature_importances = pd.Series(XGB.feature_importances_, index=Predictors) feature_importances.nlargest(10).plot(kind='barh') #Printing some sample values of prediction TestingDataResults=pd.DataFrame(data=X_test, columns=Predictors) TestingDataResults['TargetColumn']=y_test TestingDataResults['Prediction']=prediction TestingDataResults.head() |
Q Explain how the KNN algorithm works?
KNN stands for K Nearest Neighbours. As the name suggests this algorithm tries to classify a new case based on K nearby points.
A Practical range for K is 2 to 10. If K=3, it means KNN will try to look for 3 nearest points.
It consists of 3 simple steps for any new point
- Find the most K number of similar(closest) points.
- Find the count of each class in those K points.
- Classify the new point as that class which is present the maximum number of times in these K points.
- In the case of regression, take the average of nearest “K” points.

As you can see in the figure. The cross is the new point and we choose K=3.
KNN will look at the nearby 3 points. It can be seen that 2 points are blue out of 3. Hence the new point is assigned to the blue class.
The next question is, how does KNN find the nearest neighbour?
It does so by measuring distances between the points.
Distance between two points can be calculated using any one of the below methods.
- Euclidean Distance: Take the difference between the coordinates of points and add it after squaring.
E.g. Two points A(2,3) and B(6,5) will have a Euclidean distance of (2-6)2 + (3-5)2 = 20

- Manhattan Distance: The sum of absolute differences between the coordinates of points.
E.g. Two points A(2,3) and B(6,5) will have a Manhattan distance of |2-6| + |3-5| = 6

- Minkowski Distance: It is the generalization of both Euclidean and Manhattan Distance. A parameter “q” drives the behaviour of the below formula.
If q = 1, Manhattan Distance
If q = 2, Euclidean Distance

Q. How to create a KNN model for Regression in R?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
###### K-Nearest Neighbour(KNN) Regression in R ####### library(FNN) library(dummies) DataForMLTrainDummy=dummy.data.frame(DataForMLTrain, sep='_', drop=F) DataForMLTestDummy=dummy.data.frame(DataForMLTest, sep='_', drop=F) # Making Sure the Datatype is numeric for each column DataForMLTrainDummy=sapply(DataForMLTrainDummy,as.numeric) DataForMLTestDummy=sapply(DataForMLTestDummy,as.numeric) # Choosing all other colums except target variable PredictorDataForTraining <- data.matrix(DataForMLTrainDummy[, -3]) PredictorDataForTesting <- data.matrix(DataForMLTestDummy[, -3]) # Choosing only the TargetVariable from data TargetVariableForTraining<- data.matrix(DataForMLTrainDummy[, 3]) # Fitting the predictive model on training data Model_KNN=knn.reg(train=PredictorDataForTraining, y=TargetVariableForTraining, k=3) # Measuring Goodness of Fit using R2 value on TRAINING DATA Orig=DataForMLTrain$Weight Pred=Model_KNN$pred R2= 1 - (sum((Orig-Pred)^2)/sum((Orig-mean(Orig))^2)) print(paste('R2 Value is:',round(R2,4))) # Predictions of model on Testing data Model_KNN=knn.reg(train=PredictorDataForTraining, y=TargetVariableForTraining, test=PredictorDataForTesting, k=3) DataForMLTest$Prediction=Model_KNN$pred head(DataForMLTest) # Calculating the Absolute Percentage Error for each prediction in TESTING DATA LM_APE= 100 *(abs(DataForMLTest$Prediction -DataForMLTest$Weight)/DataForMLTest$Weight) print(paste('### Mean Accuracy of KNN Model is: ', 100 - mean(LM_APE))) print(paste('### Median Accuracy of KNN Model is: ', 100 - median(LM_APE))) |
Q. How to create a KNN model for Classification in R?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
###### K-Nearest Neighbour(KNN) Classification in R ####### # Preparing Data for KNN X_train=DataForMLTrain[,c('CIBIL','AGE','SALARY')] X_test=DataForMLTest[,c('CIBIL','AGE','SALARY')] y_train=DataForMLTrain[,c('APPROVE_LOAN')] y_test=DataForMLTest[,c('APPROVE_LOAN')] # Creating the model on TRAINING data library(class) Model_KNN=knn(train=X_train, test=X_test, cl=y_train , k=3) # Checking Accuracy of model on Testing data DataForMLTest$Prediction=Model_KNN head(DataForMLTest) # Creating the Confusion Matrix to calculate overall accuracy, precision and recall on TESTING data library(caret) AccuracyResults=confusionMatrix(DataForMLTest$Prediction, DataForMLTest$APPROVE_LOAN, mode = "prec_recall") # Since AccuracyResults is a list of multiple items, fetching useful components only AccuracyResults[['table']] AccuracyResults[['byClass']] print(paste('### Overall Accuracy of KNN Model is: ', round(100 * AccuracyResults[['overall']][1]) , '%')) |
Q. How to create a KNN model for Regression in Python?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
###### K-Nearest Neighbour(KNN) Regression in Python ####### from sklearn.neighbors import KNeighborsRegressor RegModel = KNeighborsRegressor(n_neighbors=2) #Printing all the parameters of KNN print(RegModel) #Creating the model on Training Data KNN=RegModel.fit(X_train,y_train) prediction=KNN.predict(X_test) #Measuring Goodness of fit in Training data from sklearn import metrics print('R2 Value:',metrics.r2_score(y_train, KNN.predict(X_train))) #Measuring accuracy on Testing Data print('Accuracy',100- (np.mean(np.abs((y_test - prediction) / y_test)) * 100)) #Plotting the feature importance for Top 10 most important columns #There is no built-in method to get feature importance in KNN #Printing some sample values of prediction TestingDataResults=pd.DataFrame(data=X_test, columns=Predictors) TestingDataResults[TargetVariable]=y_test TestingDataResults[('Predicted'+TargetVariable)]=prediction TestingDataResults.head() |
Q. How to create a KNN model for Classification in Python?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
###### K-Nearest Neighbour(KNN) Classification in Python ####### import pandas as pd from sklearn.neighbors import KNeighborsClassifier clf = KNeighborsClassifier(n_neighbors=2) #Printing all the parameters of KNN print(clf) #Creating the model on Training Data KNN=clf.fit(X_train,y_train) prediction=KNN.predict(X_test) #Measuring accuracy on Testing Data from sklearn import metrics print(metrics.classification_report(y_test, prediction)) print(metrics.confusion_matrix(y_test, prediction)) #Plotting the feature importance for Top 10 most important columns #There is no built-in method to get feature importance in KNN #Printing some sample values of prediction TestingDataResults=pd.DataFrame(data=X_test, columns=Predictors) TestingDataResults['TargetColumn']=y_test TestingDataResults['Prediction']=prediction TestingDataResults.head() |
Q Explain how the SVM algorithm works?
The support vector machine (SVM) is a generalization of a simple classifier called the maximal margin classifier.
SVM is preferred for classification, however, you can use it for regression as well.
Before you jump into SVM, the building blocks of SVM needs to be cleared which are listed below:
- Hyperplane
- Maximum Margin Classifier
- Support Vector Classifier
- Support Vector Machines
Maximum Margin Classifier can be used only when the classes are separated by a linear boundary, for example, look below. Out of the three lines possible to separate the red and blue regions, only one is the best line.

The lines are known as a Hyperplanes. Only one of the hyperplanes is the best one.

Concept of a Separating Hyperplane:
If there are “N” number of dimensions then, a hyperplane defined inside it has “N-1” dimensions.
If there are “N” number of dimensions then, a hyperplane defined inside it has “N-1” dimensions.
For example, if we have 2-Dimensions then the hyperplane will be a straight line drawn in it.
Look at the diagram below, The equation of the line drawn is 1 + 2X1 + 3X2 = 0. The two dimensions are X1(X-Axis) and X2(Y-Axis).

Now, if you choose some values of X1 and X2 such that 1+2X1 +3X2 > 0, then you will get the Blue region. These points are “Above” the line.
Again, if you choose some values of X1 and X2 such that 1+2X1 +3X2 < 0, then you will get the Red region. These points are “Below” the line.
You can say this line(1 + 2X1 + 3X2 = 0) is “Separating” the Red Points from the Blue Points.
Hence, this line is also known as a “Separating Hyperplane”
This Separating hyperplane also acts as a classifier. Let’s say a new point (X1n, X2n) needs to be assigned a class (Red or Blue)
If 1+2X1n +3X2n > 0 then it belongs to Blue region/Blue Class, and if If 1+2X1n +3X2n < 0 then it belongs to the Red Region/Red Class
For example, consider the point (X1=1, X2=1.2)
Substituting the values in the equation 1 + 2X1 + 3X2 we get 1+ 2*1 + 3 *1.2 = 6.6.
Now, because 6.6 >0 The point (X1=1, X2=1.2) belongs to Blue class / Blue Region
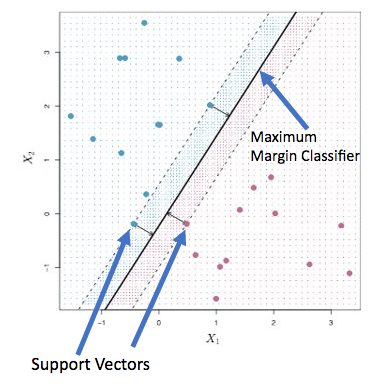
Maximum Margin classifier
Find a Separating Hyperplane in an N-dimensional space. While maximizing the perpendicular distances of the hyperplane from all the points present in training data.
That distance which is the smallest of all the perpendicular distances is known as “margin”.
A Maximum margin classifier is created when which has the largest margin.
Basically, it has the largest distance from the closest points of both all the classes.
Look at the diagram below with 2-dimensional space. With Red and Blue points. The maximum margin classifier is the one
which has maximum margin, i.e. the distance from the closest points of both classes.
Support Vector Classifier
Sometimes there is no “Separating Hyperplane” which clearly separates the data.
This is because the data points are jumbled up and there is no clear boundary between the classes.
Take a look below where the red and blue points are mixed up.
In this case, a generalized version of Maximum margin classifier is used, which is also known as support vector classifier.

The maximum margin classifier tries to classify each and every point perfectly and while doing so it can overfit and may not remain generic.
This is where the concept of “Soft margin” is applied.
“Soft margin” means the classifier is allowing a few wrong classifications in order to make the model generic.
The idea behind support vector classifier is to use a “soft margin”.
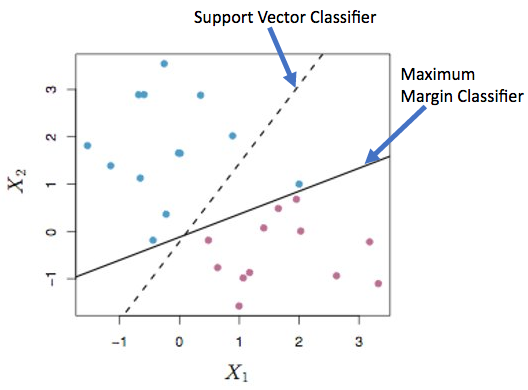
The amount of softness is controlled by a non-negative tuning parameter called “C”. If the value of C is high that means the hyperplane can have more misclassifications. If the value of C is less, then only a few misclassifications are allowed.
If the value of C=0 then it does not allow any misclassifications and hence becomes the maximum margin classifier.
“Soft margin” means the classifier is allowing a few wrong classifications in order to make the model generic.
Support Vector Machines
So far the classes were separated by a linear boundary. What if the separating boundary is non-linear?

In such cases, we should try to find an equation which is non-linear, to separate the classes.
This equation is found using “kernels” and the resulting classifier is known as support vector machines. The above diagram shows an SVM with a radial kernel, there could be linear kernels as well.
Hence, you can say that support vector machines are the extension of support vector classifier where the original data is transformed to a higher degree. e.g. linear to quadratic or cubic. so that It becomes linearly separable in that higher dimension.
Support vector machines are the extension of support vector classifier where the original data is transformed to a higher degree.
Q. How to create an SVM model for Regression in R?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
###### Support Vector Machines(SVM) Regression in R ####### library(e1071) Model_SVM=svm(formula= Weight ~ Hours+Calories,data=DataForMLTrain) # Measuring Goodness of Fit using R2 value on TRAINING DATA Orig=DataForMLTrain$Weight Pred=predict(Model_SVM, DataForMLTrain) R2= 1 - (sum((Orig-Pred)^2)/sum((Orig-mean(Orig))^2)) print(paste('R2 Value is:',round(R2,4))) # Predictions of model on Testing data DataForMLTest$Prediction=predict(Model_SVM, DataForMLTest) head(DataForMLTest) # Calculating the Absolute Percentage Error for each prediction in TESTING DATA LM_APE= 100 *(abs(DataForMLTest$Prediction - DataForMLTest$Weight)/DataForMLTest$Weight) print(paste('### Mean Accuracy of SVM Model is: ', 100 - mean(LM_APE))) print(paste('### Median Accuracy of SVM Model is: ', 100 - median(LM_APE))) |
Q. How to create an SVM model for Classification in R?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
###### Support Vector Machines(SVM) Classification in R ####### # Creating the model on TRAINING data library(e1071) Model_SVM=svm(APPROVE_LOAN~CIBIL+AGE+SALARY, data=DataForMLTrain) # Checking Accuracy of model on Testing data DataForMLTest$Prediction=predict(Model_SVM, DataForMLTest) head(DataForMLTest) # Creating the Confusion Matrix to calculate overall accuracy, precision and recall on TESTING data library(caret) AccuracyResults=confusionMatrix(DataForMLTest$Prediction, DataForMLTest$APPROVE_LOAN, mode = "prec_recall") # Since AccuracyResults is a list of multiple items, fetching useful components only AccuracyResults[['table']] AccuracyResults[['byClass']] print(paste('### Overall Accuracy of SVM Model is: ', round(100 * AccuracyResults[['overall']][1]) , '%')) |
Q. How to create an SVM model for Regression in Python?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
###### Support Vector Machines(SVM) Regression in Python ####### import pandas as pd from sklearn import svm RegModel = svm.SVR(C=2, kernel='linear') #Printing all the parameters of KNN print(RegModel) #Creating the model on Training Data SVM=RegModel.fit(X_train,y_train) prediction=SVM.predict(X_test) #Measuring Goodness of fit in Training data from sklearn import metrics print('R2 Value:',metrics.r2_score(y_train, SVM.predict(X_train))) #Measuring accuracy on Testing Data print('Accuracy',100- (np.mean(np.abs((y_test - prediction) / y_test)) * 100)) #Plotting the feature importance for Top 10 most important columns #The built in attribute SVM.coef_ works only for linear kernel %matplotlib inline feature_importances = pd.Series(SVM.coef_[0], index=Predictors) feature_importances.nlargest(10).plot(kind='barh') #Printing some sample values of prediction TestingDataResults=pd.DataFrame(data=X_test, columns=Predictors) TestingDataResults[TargetVariable]=y_test TestingDataResults[('Predicted'+TargetVariable)]=prediction TestingDataResults.head() |
Q. How to create an SVM model for Classification in Python?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
###### Support Vector Machines(SVM) Classification in Python ####### import pandas as pd from sklearn import svm clf = svm.SVC(C=2, kernel='linear') #Printing all the parameters of KNN print(clf) #Creating the model on Training Data SVM=clf.fit(X_train,y_train) prediction=SVM.predict(X_test) #Measuring accuracy on Testing Data from sklearn import metrics print(metrics.classification_report(y_test, prediction)) print(metrics.confusion_matrix(y_test, prediction)) #Plotting the feature importance for Top 10 most important columns #The built in attribute SVM.coef_ works only for linear kernel %matplotlib inline feature_importances = pd.Series(SVM.coef_[0], index=Predictors) feature_importances.nlargest(10).plot(kind='barh') #Printing some sample values of prediction TestingDataResults=pd.DataFrame(data=X_test, columns=Predictors) TestingDataResults['TargetColumn']=y_test TestingDataResults['Prediction']=prediction TestingDataResults.head() |
Conclusion
This post covers the major supervised machine learning algorithms. With these algorithms under your toolkit, you can easily solve any supervised machine learning algorithm with good accuracy.
Learning never ends though! There are more supervised ML algorithms which you should explore further. I recommend the book Introduction to Statistical Learning(ISLR) to take a deeper dive into the above listed and many more algorithms.
In the next post, I will answer the interview questions from Unsupervised Machine Learning section.
All the best for that Interview!

Indeed G8! web based tutorial , you made the complex critical knowledge simple. The examples and its illustration are powerful to understand the things in depth.
Thank you Dr. Shailendra! Means a lot when it is coming from you.
Great Sir , This has been a good platform for knowledge gathering and building a Strong Foundation on Data Science .Blogs will be like Bible for emerging students.
Thank you Biswajit! I am glad you found it useful!
I can’t thank you enough