Before you put the ML model into production, it must be tested for accuracy. This is why we split the available data into training and testing. Typically 70% for training and the remaining 30% for testing the model. Why it is like this? you can understand the logic behind it here in this post as well as in the below video.
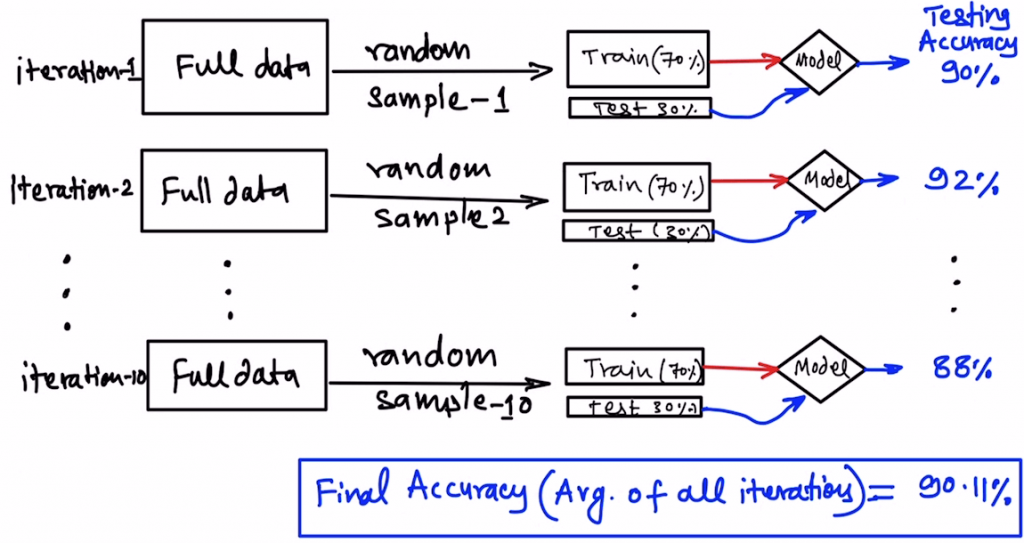
This activity of splitting the data randomly is called sampling. Now when you are measuring the accuracy of machine learning models, there is a chance that the sample which you have got is lucky! It means that the accuracy may come high due to the lucky split of data in a way where the testing data has very similar rows to training data, hence the model will perform better!
To rule out this luck factor, we try to perform sampling multiple times by changing the seed value in the train_test_split() function. This is called Bootstrapping. simply put, splitting the data into training and testing randomly “multiple times”.
How many times? Well, at least 5-times so that you are sure, the testing accuracy which you are getting was not just by chance, it is similar for all the different samples.
The final accuracy is the average of the accuracies from all sampling iterations.
You can learn about different types of sampling in the below video.
In the below code I will show you how to test a decision tree regressor model using bootstrapping. The same concept applies to any other supervised ml algorithm.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
import pandas as pd import numpy as np ColumnNames=['Hours','Calories', 'Weight'] DataValues=[[ 1.0, 2500, 95], [ 2.0, 2000, 85], [ 2.5, 1900, 83], [ 3.0, 1850, 81], [ 3.5, 1600, 80], [ 4.0, 1500, 78], [ 5.0, 1500, 77], [ 5.5, 1600, 80], [ 6.0, 1700, 75], [ 6.5, 1500, 70]] #Create the Data Frame GymData=pd.DataFrame(data=DataValues,columns=ColumnNames) GymData.head() #Separate Target Variable and Predictor Variables TargetVariable='Weight' Predictors=['Hours','Calories'] X=GymData[Predictors].values y=GymData[TargetVariable].values #### Bootstrapping #### ######################################################## # Creating empty list to hold accuracy values AccuracyValues=[] n_times=5 ## Performing bootstrapping for i in range(n_times): #Split the data into training and testing set from sklearn.model_selection import train_test_split # Chaning the seed value for each iteration X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42+i) ######################################################## ###### Single Decision Tree Regression in Python ####### from sklearn import tree #choose from different tunable hyper parameters RegModel = tree.DecisionTreeRegressor(max_depth=3,criterion='mse') #Creating the model on Training Data DTree=RegModel.fit(X_train,y_train) prediction=DTree.predict(X_test) #Measuring accuracy on Testing Data Accuracy=100- (np.mean(np.abs((y_test - prediction) / y_test)) * 100) # Storing accuracy values AccuracyValues.append(np.round(Accuracy)) ################################################ # Result of all bootstrapping trials print(AccuracyValues) # Final accuracy print('Final average accuracy',np.mean(AccuracyValues)) |
Sample Output:

In the next post, I will talk about another popular method for testing machine learning models known as k-fold cross-validation.
