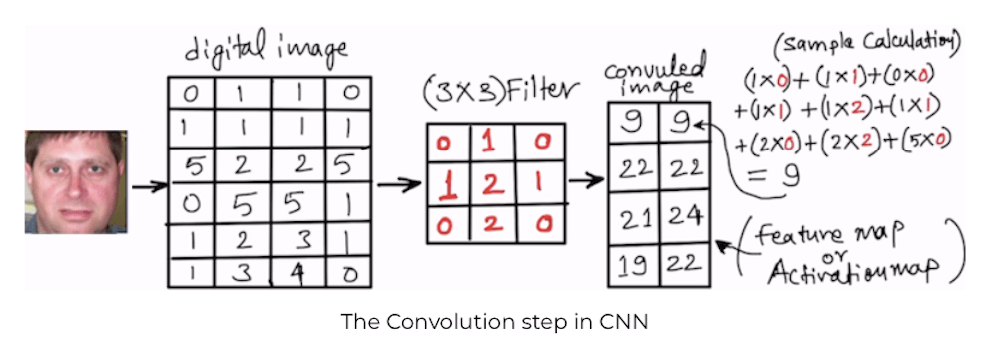
Convolutional Neural Networks(CNN) changed the way we used to learn images. It made it very very easy! CNN mimics the way humans see images, by focussing on one portion of the image at a time and scanning the whole image.
CNN boils down every image as a vector of numbers, which can be learned by the fully connected Dense layers of ANN. More information about CNN can be found here.
You can understand this case study in depth via this video below! It provides the CNN algorithm explanation and line by line code walkthrough.
Let me know if you liked this code walkthrough video in the youtube comments and if I should make more of these! Cheers!
Below diagram summarises the overall flow of CNN algorithm.

In this case study, I will show you how to implement a face recognition model using CNN. You can use this template to create an image classification model on any group of images by putting them in a folder and creating a class.
Getting Images for the case study
You can download the data required for this case study here.
Please download the updated Jupyter notebook here.
The data contains cropped face images of 16 people divided into Training and testing. We will train the CNN model using the images in the Training folder and then test the model by using the unseen images from the testing folder, to check if the model is able to recognise the face number of the unseen images or not.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
# Deep Learning CNN model to recognize face '''This script uses a database of images and creates CNN model on top of it to test if the given image is recognized correctly or not''' '''####### IMAGE PRE-PROCESSING for TRAINING and TESTING data #######''' # Specifying the folder where images are present TrainingImagePath='/Users/farukh/Python Case Studies/Face Images/Final Training Images' from keras.preprocessing.image import ImageDataGenerator # Understand more about ImageDataGenerator at below link # https://blog.keras.io/building-powerful-image-classification-models-using-very-little-data.html # Defining pre-processing transformations on raw images of training data # These hyper parameters helps to generate slightly twisted versions # of the original image, which leads to a better model, since it learns # on the good and bad mix of images train_datagen = ImageDataGenerator( shear_range=0.1, zoom_range=0.1, horizontal_flip=True) # Defining pre-processing transformations on raw images of testing data # No transformations are done on the testing images test_datagen = ImageDataGenerator() # Generating the Training Data training_set = train_datagen.flow_from_directory( TrainingImagePath, target_size=(64, 64), batch_size=32, class_mode='categorical') # Generating the Testing Data test_set = test_datagen.flow_from_directory( TrainingImagePath, target_size=(64, 64), batch_size=32, class_mode='categorical') # Printing class labels for each face test_set.class_indices |

Creating a mapping for index and face names
The above class_index dictionary has face names as keys and the numeric mapping as values. We need to swap it, because the classifier model will return the answer as the numeric mapping and we need to get the face-name out of it.
Also, since this is a multi-class classification problem, we are counting the number of unique faces, as that will be used as the number of output neurons in the output layer of fully connected ANN classifier.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
'''############ Creating lookup table for all faces ############''' # class_indices have the numeric tag for each face TrainClasses=training_set.class_indices # Storing the face and the numeric tag for future reference ResultMap={} for faceValue,faceName in zip(TrainClasses.values(),TrainClasses.keys()): ResultMap[faceValue]=faceName # Saving the face map for future reference import pickle with open("ResultsMap.pkl", 'wb') as fileWriteStream: pickle.dump(ResultMap, fileWriteStream) # The model will give answer as a numeric tag # This mapping will help to get the corresponding face name for it print("Mapping of Face and its ID",ResultMap) # The number of neurons for the output layer is equal to the number of faces OutputNeurons=len(ResultMap) print('\n The Number of output neurons: ', OutputNeurons) |

Creating the CNN face recognition model
In the below code snippet, I have created a CNN model with
- 2 hidden layers of convolution
- 2 hidden layers of max pooling
- 1 layer of flattening
- 1 Hidden ANN layer
- 1 output layer with 16-neurons (one for each face)
You can increase or decrease the convolution, max pooling, and hidden ANN layers and the number of neurons in it.
Just keep in mind, the more layers/neurons you add, the slower the model becomes.
Also, when you have large amount of images, in the tune of 50K and above, then your laptop’ CPU might not be efficient to learn those many images. You will have to get a GPU enabled laptop, or use cloud services like AWS or Google Cloud.
Since the data we have used for the demonstration is small containing only 244 images for training, you can run it on your laptop easily 🙂
Apart from selecting the best number of layers and the number of neurons in it, for each layer, there are some hyper parameters which needs to be tuned as well.
Take a quick look at some of the important hyperparameters
- Filters=32: This number indicates how many filters we are using to look at the image pixels during the convolution step. Some filters may catch sharp edges, some filters may catch color variations some filters may catch outlines, etc. In the end, we get important information from the images. In the first layer the number of filters=32 is commonly used, then increasing the power of 2. Like in the next layer it is 64, in the next layer, it is 128 so on and so forth.
- kernel_size=(5,5): This indicates the size of the sliding window during convolution, in this case study we are using 5X5 pixels sliding window.
- strides=(1, 1): How fast or slow should the sliding window move during convolution. We are using the lowest setting of 1X1 pixels. Means slide the convolution window of 5X5 (kernal_size) by 1 pixel in the x-axis and 1 pixel in the y-axis until the whole image is scanned.
- input_shape=(64,64,3): Images are nothing but matrix of RGB color codes. during our data pre-processing we have compressed the images to 64X64, hence the expected shape is 64X64X3. Means 3 arrays of 64X64, one for RGB colors each.
- kernel_initializer=’uniform’: When the Neurons start their computation, some algorithm has to decide the value for each weight. This parameter specifies that. You can choose different values for it like ‘normal’ or ‘glorot_uniform’.
- activation=’relu’: This specifies the activation function for the calculations inside each neuron. You can choose values like ‘relu’, ‘tanh’, ‘sigmoid’, etc.
- optimizer=’adam’: This parameter helps to find the optimum values of each weight in the neural network. ‘adam’ is one of the most useful optimizers, another one is ‘rmsprop’
- steps_per_epoch= 8: This specifies how many rows will be passed to the Network in one go after which the error calculation will begin and the neural network will start adjusting its weights based on the errors.
When all the rows are passed in the batches of 8 rows each as specified in this parameter, then we call that 1-epoch. Or one full data cycle. - Epochs=60: The same activity of adjusting weights continues for 60 times, as specified by this parameter. In simple terms, the CNN looks at the full training data 60 times and adjusts its weights. Tune this based on your accuracy value.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
'''######################## Create CNN deep learning model ########################''' from keras.models import Sequential from keras.layers import Convolution2D from keras.layers import MaxPool2D from keras.layers import Flatten from keras.layers import Dense '''Initializing the Convolutional Neural Network''' classifier= Sequential() ''' STEP--1 Convolution # Adding the first layer of CNN # we are using the format (64,64,3) because we are using TensorFlow backend # It means 3 matrix of size (64X64) pixels representing Red, Green and Blue components of pixels ''' classifier.add(Convolution2D(32, kernel_size=(5, 5), strides=(1, 1), input_shape=(64,64,3), activation='relu')) '''# STEP--2 MAX Pooling''' classifier.add(MaxPool2D(pool_size=(2,2))) '''############## ADDITIONAL LAYER of CONVOLUTION for better accuracy #################''' classifier.add(Convolution2D(64, kernel_size=(5, 5), strides=(1, 1), activation='relu')) classifier.add(MaxPool2D(pool_size=(2,2))) '''# STEP--3 FLattening''' classifier.add(Flatten()) '''# STEP--4 Fully Connected Neural Network''' classifier.add(Dense(64, activation='relu')) classifier.add(Dense(OutputNeurons, activation='softmax')) '''# Compiling the CNN''' #classifier.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) classifier.compile(loss='categorical_crossentropy', optimizer = 'adam', metrics=["accuracy"]) ########################################################### import time # Measuring the time taken by the model to train StartTime=time.time() # Starting the model training classifier.fit_generator( training_set, steps_per_epoch=8, epochs=60, validation_data=test_set, validation_steps=4) EndTime=time.time() print("###### Total Time Taken: ", round((EndTime-StartTime)/60), 'Minutes ######') |

Testing the CNN classifier on unseen images
Using any one of the images from the testing data folder, we can check if the model is able to recognize the face.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
'''########### Making single predictions ###########''' import numpy as np from keras.preprocessing import image ImagePath='/Users/farukh/Python Case Studies/Face Images/Final Testing Images/face4/3face4.jpg' test_image=image.load_img(ImagePath,target_size=(64, 64)) test_image=image.img_to_array(test_image) test_image=np.expand_dims(test_image,axis=0) result=classifier.predict(test_image,verbose=0) #print(training_set.class_indices) print('####'*10) print('Prediction is: ',ResultMap[np.argmax(result)]) |

The model has predicted this face correctly! You can try for other faces and see if it gets recognized. You can also add your own pics and train the model again.
Conclusion
You can modify this template to create a classification model for any group of images. Just put the images of each category in its respective folder and train the model.
The CNN algorithm has helped us create many great applications around us! Facebook is the perfect example! It has trained its DeepFace CNN model on millions of images and has an accuracy of 97% to recognize anyone on Facebook. This may surpass even humans! as you can remember only a few faces 🙂
CNN is being used in the medical industry as well to help doctors get an early prediction about benign or malignant cancer using the tumor images. Similarly, get an idea about typhoid by looking at the X-ray images, etc.
The usage of CNN are many, and developing fast around us!
I hope after reading this post, you are little more confident about implementing CNN algorithm for some use cases in your projects!

ResultMap[faceValue]=faceName getting error for this line, could you please help
Can you tell me please that how you solved this problem?
Able to solve the issue I was getting , wonderful article, many thanks for sharing
Thank you Suman!
I am glad you liked it!
There cannot be better site to understand CNN fundamentals, well explained Farukh
Thank you for the kind words Vivek!
Will this categorize the image not in the training set ?
Hi Ola,
Yes, the test folder which has been used in the example for single predictions was totally unseen by the model.
For other implementations, just make sure the target size of the image is same as the training data while passing a new image to check.
ResultMap={}
for faceValue,faceName in zip(TrainClasses.values(),TrainClasses.keys()):
ResultMap[faceValue]=faceName
reply correct code?
Hi Sunny,
What is the exact issue you are facing, can you send me a screenshot of the command and error, I will be able to help.
me also face that issue by deepak
I am getting an error while training the model, I get:
WARNING:tensorflow:Your input ran out of data; interrupting training. Make sure that your dataset or generator can generate at least
steps_per_epoch * epochsbatches (in this case, 100 batches). You may need to use the repeat() function when building your dataset.So the training is not working and the accuracy is 0.0492, should I change anything?
Hi Andres,
Please use a smaller steps_per_epoch value.
Regards,
Farukh Hashmi
Just fixed it, the steps_per_epoch value must be set to 8
Great!!
Whatever total epoch may be 10 or 8 , the accuracy level is always less than 0.07 and model could not identify correctly, any one image, I tried, for several attempts .
Hi Amalendu,
Can you try once by increasing the neurons in the Dense layer to 128 or 150?
Let me know if it works.
Regards,
Farukh Hashmi
I have the same issue and tried increasing dense layer and it still identifies incorrectly with very low accuracy level, help!
Hi Abdullah,
Are you using the same data as the case study?
Can you share a little more information about the data/config so that I can help
Regards
Farukh Hashmi
I have my own data for training this model but can you tell me where is the split_data code? Are you splitting data before training because the training and test data both have same path i.e TrainingImagePath?
Hi Amir,
The split happens based on the folder itself. I have used train and test as the same images and kept the testing folder images to check the model performance in the last section manually.
If you want to split your data, please keep them in separate folders and provide different path for training and testing.
Hope that helps!
Regards,
Farukh Hashmi
Hi,
I would like to ask what version of keras are you using for this. I keep getting this error:
from tensorglow.python.eager.context import get_config
ImportError: Cannot import name ‘get_config’
I have found some solutions online and they mentioned that it may be the version of the library that causes this error when we are copying someones code.
HI,
I would like to ask what version of keras was used in this as I have the following error:
from tensorflow.python.eager.context ‘get_config’
ImportError: cannot import name ‘get_config’
I have found some solutions online and 1 of the solutions is that it may be the difference in versions of the library.
Hi,
I would like to know what version of Keras was used here as i have encountered the following error:
from tensorflow.python.eager.context import get_config
ImportError: cannot import name ‘get_config’
I have searched online for the cause of this error and it was mentioned that the version of Keras might be a possibility. Thanks
hai farukh hashmi
so thanks for that program provided
hey sir!
I got a problem with the testing.
the image location is working in other place but here Traceback error ” No such file directory”
Hi Muhammad,
Can you share the screenshot of error. I might be able to help.
is the best article! thank u guys!!
Hi there,
For the testing part, I’m receiving this :-
“AttributeError: module ‘keras.preprocessing.image’ has no attribute ‘load_img'”
Please help me out in this part.
try using “from tensorflow.keras.preprocessing import image” instead of keras.preprocessing.image’ import load_img’”
how can we use this for live vedio detecting ?? as the model is trained??
from this trained model is any one have done live recognition through webcam please do letb me know
Hi, this is really helpful. I tried the code and data, and it worked. But the result always is wrong. Does this result make sense? Thank you!
Hi Alicia!
Can you try by increasing the number of neurons in the hidden layer to 128 or 150 etc. The accuracy will increase with parameter tuning if you are not getting it out of the box code.
Regards
Farukh Hashmi
Hey,
I am getting this error
WARNING:tensorflow:Your input ran out of data; interrupting training. Make sure that your dataset or generator can generate at least steps_per_epoch * epochs batches (in this case, 100 batches). You may need to use the repeat() function when building your dataset.
I tried reducing the steps per epoch, but still I am getting the error.
Also I have a dataset of 10 people having 100 images each. But the accuracy I am getting is around 9%, which is very low. Also I have observed that when I train the model with 2 images the accuracy is around 50% and for 10 images it is around 10%.. if you are aware of why this is happening Please let me! Thanks.
training_set = train_datagen.flow_from_directory(
TrainingImagePath,
target_size=(64, 64),
batch_size=32,
class_mode=’categorical’)
getting error in this line saying file not found error. please help
Hello Dear …
I need, very importantly, a code to classify masked faces using ٍSaimese networks if available.
Thank you